Autonomous QA For Mobile Apps Across 150+ Real Devices
A swarm of agents runs your app 24/7, crawling every workflow, testing every interaction, and surfacing what works, what breaks, and what needs improvement with zero human effort.
Trusted by brands, across the globe
One report. Every device. Both platforms.
Pulled from a run across 150+ real Android and iOS devices, with the root cause already worked out, not just a pass or fail.
Tested on the phones your users actually carry
Not one emulator. These are 8 of the 150+ real device and OS combinations we run every release, so a Pixel-only crash never reaches a release looking like a clean pass.
Pass rate by device × OS
| Device | OS | Tests run | Pass rate | Status |
|---|---|---|---|---|
| Pixel 9 | Android 14 | 788 | 34% | Problem |
| Pixel 9 | Android 15 | 312 | 82% | Stable |
| OnePlus 11 | Android 13 | 768 | 45% | Watch |
| Galaxy S23 Ultra | Android 13 | 665 | 46% | Watch |
| Galaxy S24 | Android 14 | 230 | 51% | Watch |
| Pixel 10 Pro XL | Android 14 | 662 | 44% | Problem |
| iPhone 16 Pro | iOS 18 | 91 | 79% | Stable |
| iPhone 17 Pro | iOS 26 | 60 | 73% | New device |
Catches the bugs that only show up on one platform
163 errors this week, every one of them on Android. The same flows pass on iOS, which points straight at an SDK or OS issue instead of a code review.
Platform split
Android
43%
4,205 tests · 163 errors
iOS
59%
151 tests · 12 errors
Worst combo
Pixel 9 · A14
34% pass
Best combo
iPhone 16 · iOS 18
79% pass
A number for every release decision, not just a percentage
Stability score, pass rate, and bugs caught update after every run, so "are we ready to ship" has an answer before someone has to ask.
Stability score
0
▲ +11 vs prev week
Pass rate
0%
▼ -4% vs prev week
Bugs detected
0
0 in production
AI-authored flows
0
▲ +14 vs prev week
Consistently failing
0
5+ consecutive runs
Flaky flows
0
Pass-fail pattern
Resolved this week
0
Within 48h SLA
Avg detection time
0 min
▼ -41 min vs prev week
Watches the app, not just the test script
Memory, startup time, and frame rate get tracked across every run, so a slow leak shows up days before a user ever files a complaint.
↑ Memory regression across the last 5 runs
242MB to 302MB, a 25% increase, while FPS and crash rate stay flat.
Aggregated across all devices this period
Cold startup
0ms
▲ +13%
Hot startup
0ms
Stable
Max memory
0MB
▲ +24%
Avg memory
0MB
▲ +18%
Max CPU
0%
▼ -2%
Avg FPS
0FPS
Stable
Freeze frames
0%
▲ +0.4%
Janky frames
0%
Normal
Battery / session
0%
Stable
Network DL
0KB
Normal
App crashes
0
None
ANR events
0
None
Memory trend
CPU trend
Cold startup time
Every screen. Every tap. Automatically.
No test scripts. No setup. Runs on 150+ real devices and finds what your testers miss.
Drop your mobile app and start testing in seconds
Automate Mobile Workflows at Production Scale
Turn feature descriptions into stable mobile tests that run the same way every time.

Deterministic Test Generation
Appium. Maestro. No LLMs
Device Farm and CI Ready
150+ devices.CI native
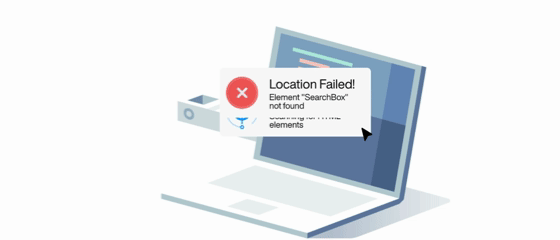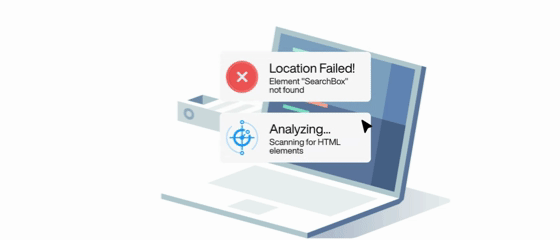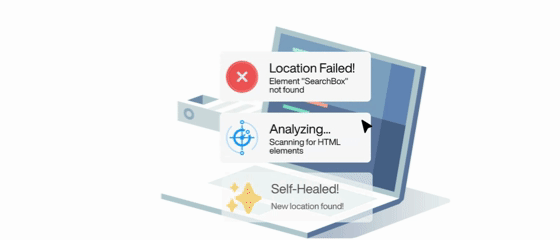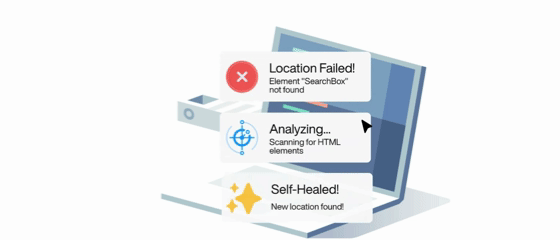
Self Healing and Maintenance Free
Auto Fix Broken Tests
Real Device First Execution
Not Emulators. Real Flows
Mock Data and Auth Handling
Otp's, Credentials, API's

Deep Failure Visibility
Logs, Videos, Traces
End to End Flow Orchestration
Dashboard, Slack, CI

Release Confidence Gates
Block Bad Builds Early
Automated Test Case
Understands natural language and your org context. Generates smart test cases automatically.
Reports
Get step-by-step debug reports with logs, videos, and screenshots — delivered to Slack or your dashboard.
Self-Healing
No manual updates needed. The agent adapts to UI changes, updates test cases automatically, and keeps you informed.
Speed
Create, execute and run mobile test cases in natural language. Instant test reports just like human, but better.




FAQ's
- Understand requirements in natural language or automatically generate test cases tailored to your organization’s context.
- Execute tests on real devices or emulators.
- Automated tests run across multiple devices and frequencies in a fraction of the time.
- Self-heal broken automations when the UI changes — remapping journeys, adapting to updates, and providing feedback automatically.