
Automated testing with Selenium and Playwright has become a foundational part of modern software delivery.
These frameworks enable teams to validate functionality across browsers, simulate user behavior, and catch regressions before production.
However, even mature automation suites face persistent challenges: flaky tests that fail intermittently, slow debugging cycles that even traditional assertions cannot detect.
By layering AI capabilities onto an existing Selenium or Playwright stack, teams can move from reactive testing to predictive and intelligent quality assurance.
Instead of rewriting your automation from scratch, the goal is to augment what already works.
Prerequisites of Integration
Before integrating AI into your Selenium or Playwright environment, ensure a few fundamentals are in place.
1. Programming Knowledge
You should be comfortable with at least one of the following:
- JavaScript or TypeScript (common with Playwright)
- Python or Java (common with Selenium)
AI integrations typically involve SDKs, APIs, or lightweight ML scripts—so basic coding fluency is essential.
2. Existing Test Automation Setup
You need a working automation framework, including:
- Stable test execution in CI/CD
- Organized test suites and reporting
- Reliable environment configuration
AI improves an existing system—it cannot compensate for a completely unstable foundation.
3. Basic AI/ML Awareness
You don’t need to be a data scientist, but understanding concepts like:
- Model training vs inference
- Classification and defect detection
- Confidence scores and thresholds
…will help you interpret AI-generated insights correctly.
4. Tools and Libraries
Common categories include:
Visual AI testing
- Applitools
- Percy
Custom AI / ML
- TensorFlow.js
- PyTorch
Infrastructure
- GitHub or GitLab repositories
- CI/CD pipelines like Jenkins or GitHub Actions
With these prerequisites ready, integration becomes significantly smoother.
Choosing the Right AI Approach for Your Stack
AI in testing isn’t a single feature—it’s a range of capabilities that enhance different stages of your automation lifecycle.
Some approaches focus on what users see (visual validation), others on how tests behave over time (predictive insights), and newer ones on how tests are written (natural-language generation).
The best place to start depends on:
- Team maturity and stability of your current suite
- Biggest pain point (UI bugs, flaky CI, slow test creation)
- Budget and tooling constraints
Most teams begin with the highest immediate ROI, then expand gradually.
1. Visual AI Testing
Best for: Catching UI regressions, layout shifts, and cross-browser rendering issues.
Traditional UI checks rely on DOM assertions or pixel comparisons, which are brittle and noisy. Visual AI instead evaluates whether a page looks meaningfully different to a human, reducing false alarms while still catching real design issues.
Benefits
- Works consistently across browsers and screen sizes
- Ignores minor pixel noise and dynamic content changes
- Requires little to no ML expertise
- Quick to integrate into existing Selenium or Playwright tests
Limitations
- Many mature tools are paid
- Baseline screenshots must be updated after redesigns
- Dynamic regions may need masking rules
Because it delivers fast, visible impact without needing historical data, visual AI is often the best first step into AI-driven QA.
2. Predictive Test Analysis
Best for: Identifying flaky or high-risk tests before they fail in CI/CD.
Flaky tests reduce trust in automation and slow releases. Predictive analysis uses historical signals—like pass/fail trends, retries, and execution time—to estimate a test’s failure probability and highlight instability early.
Benefits
- Improves CI reliability and developer confidence
- Surfaces meaningful failures instead of noise
- Enables smarter test prioritization and faster pipelines
- Reveals hidden instability patterns over time
Limitations
- Requires sufficient historical execution data
- Needs lightweight modeling or analytics setup
- Must be tuned as the system evolves
This approach is especially valuable for large or slow test suites, where smarter execution can save significant time.
3. Natural Language to Test Generation
Best for: Speeding up creation of automated tests from plain-language requirements or user stories.
Natural-language AI can translate prompts into starter Selenium or Playwright scripts, helping teams expand coverage faster and involve non-engineers in QA.
Benefits
- Rapid creation of new test scenarios
- Enables collaboration from manual QA or product teams
- Reduces repetitive boilerplate coding
- Can suggest hints or edge cases to validate
Limitations
- Generated tests still need human review
- Reliability and selector accuracy can vary
- Context awareness may be limited
For now, this approach works best as an assistive drafting tool, not a fully autonomous solution—but it’s evolving quickly.
Where Most Teams Should Begin
A simple guideline:
- Frequent UI regressions? → Start with Visual AI
- Flaky or slow CI pipelines? → Add Predictive Analysis
- Test creation bottlenecks? → Use Natural-Language Generation
Over time, combining these approaches creates an automation stack that is visually aware, risk-driven, and AI-assisted—a major step toward truly intelligent QA.
Step-by-Step Integration Guide
1. Installing AI Dependencies
Start by adding the necessary AI SDKs to your project, just as you would introduce any new testing utility.
The key here is to treat AI as an enhancement layer, not a hard dependency that could break your existing automation flow.
Install only what you need for your initial experiment—typically a visual AI SDK or a lightweight ML library—so you can validate value quickly without increasing maintenance overhead.
It’s also a good practice to:
- Keep AI packages version-pinned to avoid unexpected CI failures
- Load AI features conditionally (for example, only in certain test suites or environments)
- Separate AI configuration through environment variables or feature flags
This ensures your core Selenium or Playwright execution remains stable, fast, and independent, even if AI services are temporarily unavailable.
For visual AI with Playwright:
npm install @applitools/eyes-playwright
For lightweight ML experimentation:
npm install @tensorflow/tfjs
Keep AI dependencies modular and optional so they don’t block core test execution.
2. Connecting AI with Selenium or Playwright
Once dependencies are installed, the next step is to embed AI checks into real test flows rather than building separate experimental scripts.
The most effective integrations happen when AI runs alongside your normal assertions, capturing additional intelligence without changing how tests are structured or executed.
In practice, this means:
- Opening an AI validation session at the same point a user journey begins
- Capturing visual or behavioral checkpoints during navigation
- Closing the AI session in sync with test completion so results appear in CI reports
Because the AI layer operates externally, your original selectors, waits, and assertions remain untouched. This makes adoption low risk and reversible, which is important when introducing new tooling into production pipelines.
Example: Playwright with visual AI validation.
const { chromium } = require('playwright');
const { Eyes, Target } = require('@applitools/eyes-playwright');
(async () => {
const browser = await chromium.launch();
const context = await browser.newContext();
const page = await context.newPage();
const eyes = new Eyes();
eyes.setApiKey(process.env.APPLITOOLS_API_KEY);
try {
await eyes.open(page, 'My App', 'Home Page Test');
await page.goto('https://example.com');
await eyes.check('Home Page', Target.window());
await eyes.close();
} finally {
await eyes.abortIfNotClosed();
await browser.close();
}
})();
This adds AI-driven visual validation without rewriting the test logic.
3. Adding AI-Based Test Analysis
Beyond visual validation, AI becomes especially valuable when applied to historical execution data.
Instead of waiting for flaky failures to appear in CI, lightweight models can analyze trends and estimate which tests are most likely to fail in the future.
Even simple signals—like runtime variance or retry frequency—can reveal instability patterns that humans often miss. Over time, this enables teams to shift from reactive debugging to proactive risk detection.
When integrating this layer:
- Start with a small dataset from recent CI runs
- Focus on binary outcomes (pass vs. fail probability) before complex modeling
- Surface predictions in dashboards or pull-request checks, where developers already look
The goal isn’t perfect prediction—it’s earlier visibility into risk.
Example using TensorFlow.js:
const tf = require('@tensorflow/tfjs');
const data = tf.tensor2d([
[1.2, 0], [3.4, 1], [2.1, 0], [4.0, 1]
]);
const model = tf.sequential();
model.add(tf.layers.dense({units: 1, inputShape: [2], activation: 'sigmoid'}));
model.compile({loss: 'binaryCrossentropy', optimizer: 'adam'});
await model.fit(data, tf.tensor2d([[0],[1],[0],[1]]), {epochs: 50});
const prediction = model.predict(tf.tensor2d([[2.5, 0]]));
prediction.print();
In real pipelines, inputs might include:
- Test duration trends
- Retry counts
- Failure frequency
- Environment differences
The output becomes a risk score surfaced directly in CI dashboards, helping teams prioritize investigation before failures cascade.
4. Scaling Tests Across Browsers and Devices
Running the same intelligent validation across multiple browsers, viewports, or devices ensures that insights reflect real user diversity, not just a single environment.
Without this breadth, AI may confirm that a page works in Chromium while missing layout breaks in WebKit or Firefox. Cross-environment execution turns AI from a local checker into a true quality signal.
When scaling:
- Reuse the same AI checkpoints across browsers for consistent comparison
- Prioritize customer-critical journeys instead of the full suite at first
- Monitor runtime impact to keep CI pipelines efficient
const browsers = ['chromium', 'firefox', 'webkit'];
for (const name of browsers) {
const browser = await require('playwright')[name].launch();
const page = await browser.newPage();
await page.goto('https://example.com');
// AI validation logic here
await browser.close();
}Pairing cross-browser execution with visual AI quickly reveals layout inconsistencies and rendering issues that functional assertions alone cannot detect.
5. Logging and Reporting Results
AI insights are only useful if they are visible and actionable. Instead of producing more raw logs, effective AI reporting highlights data like:
- What failed
- How severe the anomaly is
- Where to investigate first
Structured outputs—like anomaly scores, grouped screenshots, or trend summaries—allow teams to move from debugging symptoms to understanding root causes much faster.
As adoption grows, mature teams route these insights into the same places developers already monitor:
- CI dashboards for release decisions
- Slack or chat alerts for rapid awareness
- Quality analytics platforms for long-term trends
const report = {
testName: 'Home Page Test',
status: 'failed',
anomalyScore: 0.87,
screenshots: ['screenshot1.png', 'screenshot2.png']
};
console.log(JSON.stringify(report, null, 2));
The ultimate goal is faster root-cause detection with less noise—turning test automation from a simple gatekeeper into a continuous source of quality intelligence.
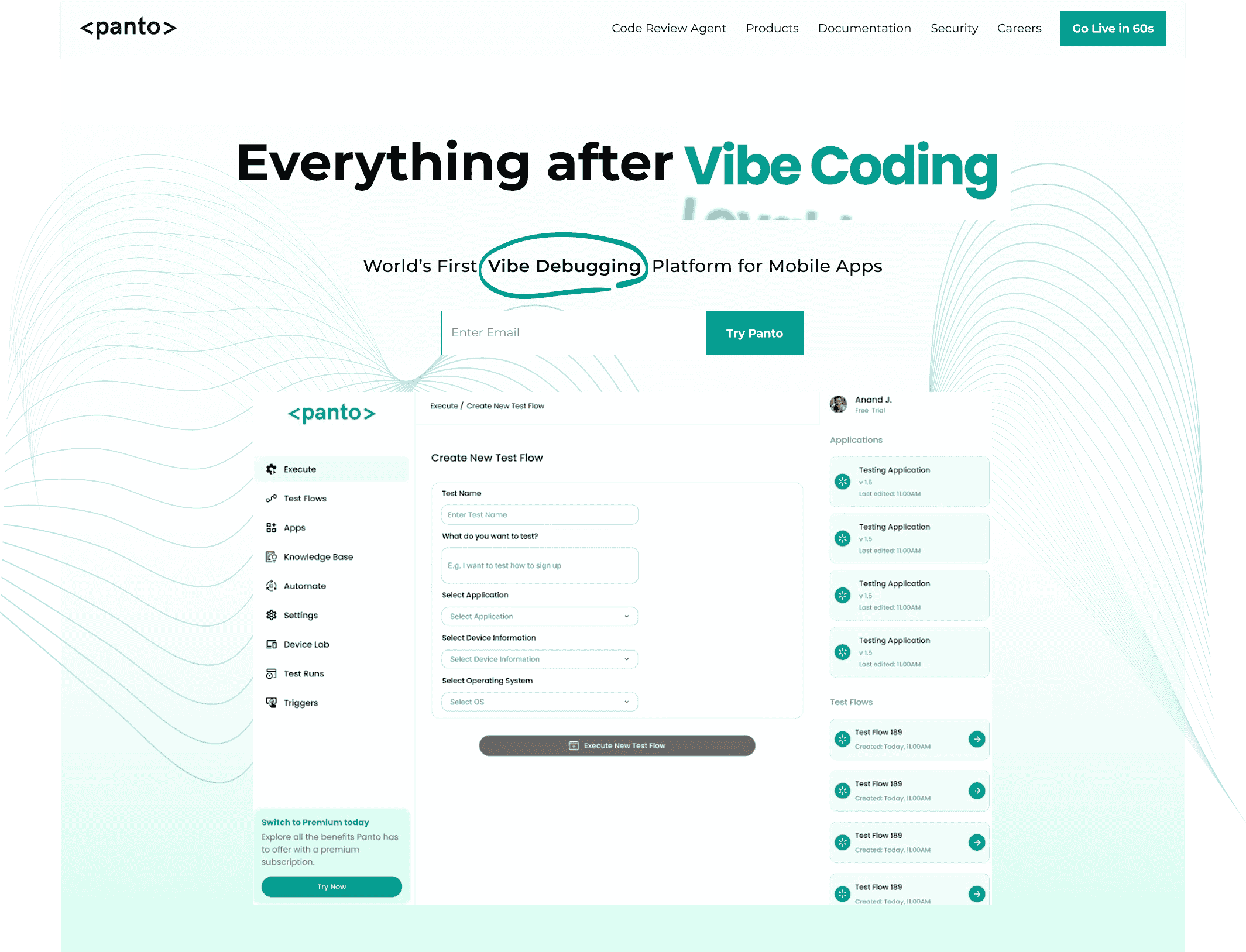
Everything After Vibe Coding
Panto AI helps developers find, explain, and fix bugs faster with AI-assisted QA—reducing downtime and preventing regressions.
- ✓ Explain bugs in natural language
- ✓ Create reproducible test scenarios in minutes
- ✓ Run scripts and track issues with zero AI hallucinations
Advanced Tips and Best Practices
Continuously Train on Fresh Data
AI correctness depends heavily on recent and relevant execution history. As your application UI, performance characteristics, and user flows evolve, older baselines or training data quickly become outdated.
If models aren’t refreshed, they may start flagging normal behavior as anomalies—or worse, miss real regressions.
To keep AI insights trustworthy:
- Periodically retrain predictive models using the latest CI results
- Refresh visual baselines after intentional UI or design updates
- Remove stale or noisy historical data that could skew predictions
Keep Humans in the Loop
AI should support QA automation decision-making, not replace it. While models can detect anomalies or predict instability, they still operate on probabilities and patterns—not full product context.
Blindly trusting AI outputs can lead to missed edge cases or unnecessary release blocks.
A balanced approach includes:
- Manually reviewing high-severity or customer-facing failures
- Using AI scores as prioritization signals, not absolute truth
- Allowing QA engineers to override or confirm AI findings
Integrate Directly into CI/CD
AI delivers the most value when its insights appear exactly where developers already make release decisions.
If results live in a separate dashboard that no one checks, adoption will stall regardless of model quality.
Instead, embed AI feedback into:
- Pull request checks that highlight visual diffs or risk scores
- CI pipeline summaries that flag flaky or high-probability failures
- Deployment gates that prevent risky releases from progressing
Start Small, Then Expand
Attempting a full AI transformation at once often creates complexity, resistance, and unclear ROI.
The most successful teams begin with focused, high-impact use cases, prove value quickly, and expand from there.
A practical rollout path looks like:
- Introduce visual AI on a few critical user journeys
- Add flaky test prediction using recent CI history
- Implement smart test prioritization to speed up pipelines
Common Pitfalls and How to Avoid Them
Misinterpreting AI Alerts
AI outputs are fundamentally probabilistic, not definitive. A high anomaly score or predicted failure risk signals that something might be wrong—it doesn’t guarantee a real defect.
Treating every AI alert as a hard failure can slow releases, create unnecessary noise, and reduce trust in the system.
To use AI responsibly:
- Validate visually significant or high-risk anomalies before blocking deployments
- Compare AI findings with logs, screenshots, and recent code changes
- Calibrate confidence thresholds so only meaningful signals surface in CI
Fix:
Use confidence thresholds combined with manual review workflows to balance speed with accuracy. This keeps AI helpful rather than disruptive.
Performance Overhead on Large Suites
AI analysis—especially visual comparison or predictive modeling—can introduce additional processing time.
When applied indiscriminately across thousands of tests, this overhead may slow CI pipelines instead of improving them. The solution is selective intelligence, not blanket coverage.
Focus AI where it delivers the most value:
- High-risk tests tied to complex or recently changed code
- Customer-critical flows that directly impact revenue or usability
- Frequently failing scenarios that consume debugging time
Fix:
Prioritize AI on the smallest set of highest-impact tests, then expand gradually once performance and ROI are clear.
Ignoring Tool Limitations
Visual AI can struggle with highly dynamic content, predictive models depend on data quality, and NLP-generation may miss application-specific nuances.
Assuming any single tool will cover every scenario leads to blind spots in quality assurance. Strong automation strategies rely on complementary validation layers, not a single source of truth.
Fix:
Combine multiple approaches:
- Visual comparison to catch UI regressions
- Statistical or predictive analysis to detect instability trends
- Traditional assertions to verify exact functional behavior
This layered validation model provides the most reliable coverage—balancing AI intelligence with deterministic checks to ensure confidence in every release.
Conclusion and Next Steps
Adding AI to an existing Selenium or Playwright stack is less about replacing automation and more about making it intelligent.
AI helps teams detect visual regressions earlier, predict instability before CI failures, reduce maintenance overhead, and accelerate confident releases.
The most successful implementations follow a clear path:
- Start with visual AI for immediate value
- Introduce predictive analytics using historical data
- Integrate insights into CI/CD decision-making
- Expand gradually across the test lifecycle
AI-assisted QA is quickly shifting from experimental advantage to competitive necessity. Teams that adopt it thoughtfully today will ship faster—and with greater confidence—tomorrow.
Next steps to explore:
- Pilot visual AI on a single critical user journey
- Collect historical test metrics for predictive modeling
- Embed AI insights directly into pull-request development workflows
- Measure improvements in flakiness, debugging time, and release speed
Small, deliberate steps can transform traditional automation into a self-improving quality system.

