
TestGrid is a solid fit for teams that want to run automation on real devices and browsers with support for Selenium, Appium, and Cypress. Its positioning is especially useful for mobile teams that want real-device cloud execution instead of a purely emulated setup.
Still, many buyers look for alternatives when they want stronger AI assistance, broader browser coverage, deeper enterprise controls, or a simpler testing workflow. The tools below are the most relevant TestGrid alternatives to consider right now.
What Is TestGrid?
TestGrid is an end-to-end testing platform that helps teams automate web, mobile, and API testing using a cloud-based infrastructure. It provides access to real Android and iOS devices, cross-browser testing environments, and support for popular frameworks such as Selenium, Appium, and Cypress.
The platform is designed to reduce the complexity of maintaining in-house device labs while enabling teams to run large-scale automated and manual tests from a single dashboard. For organizations focused on mobile application quality and compatibility testing, TestGrid offers a practical and well-established solution.
Why Look For A TestGrid Alternative?
TestGrid is a capable platform, but it may not be the ideal fit for every engineering organization. Teams often begin evaluating alternatives when they want stronger AI-driven test generation, better self-healing capabilities, deeper analytics, broader enterprise controls, or a simpler user experience.
Pricing and platform focus can also influence the decision. Some teams need a more mobile-first AI automation solution, while others prioritize large-scale device coverage, codeless automation, or advanced performance monitoring.
Ultimately, the best TestGrid alternative depends on your testing priorities. If your goal is to reduce test maintenance, accelerate release cycles, and improve reliability, comparing specialized alternatives can help you find a platform that aligns more closely with your workflow and budget.
10 Best TestGrid Alternatives
Comparison Table of TestGrid Alternatives
| Tool | Core Strength | Best For | Key Limitation |
| Panto AI | AI-first test creation and self-healing | Teams that want less maintenance and faster QA workflows | More AI-native than a classic device-cloud-only tool. |
| BrowserStack | Huge real-device and browser coverage | Teams testing web and mobile at scale | Broad platform may be more than smaller teams need. |
| LambdaTest | AI-native cloud testing for web and mobile | Teams that want parallel cloud execution | Less specialized than mobile-first tools. |
| Sauce Labs | Enterprise real-device cloud | Large QA teams needing deep diagnostics | Heavier platform for smaller teams. |
| Kobiton | Mobile-first real-device testing | Mobile product teams | More focused on mobile than full-stack QA. |
| HeadSpin | Mobile performance and observability | Teams that care about KPIs and user experience | Best when performance insight matters most. |
| Perfecto | Unified web/mobile testing with AI | Enterprise teams and script migration | Can be more platform-heavy than lightweight tools. |
| Functionize | Agentic AI test automation | Teams wanting self-healing automation | Less device-cloud centered. |
| ACCELQ | Codeless end-to-end automation | Teams that want no-code workflows across apps and APIs | Not primarily a device cloud. |
| Katalon | Broad AI testing platform | Mixed-skill QA teams across web, mobile, API, and desktop | Broad scope can mean more setup. |
1. Panto AI
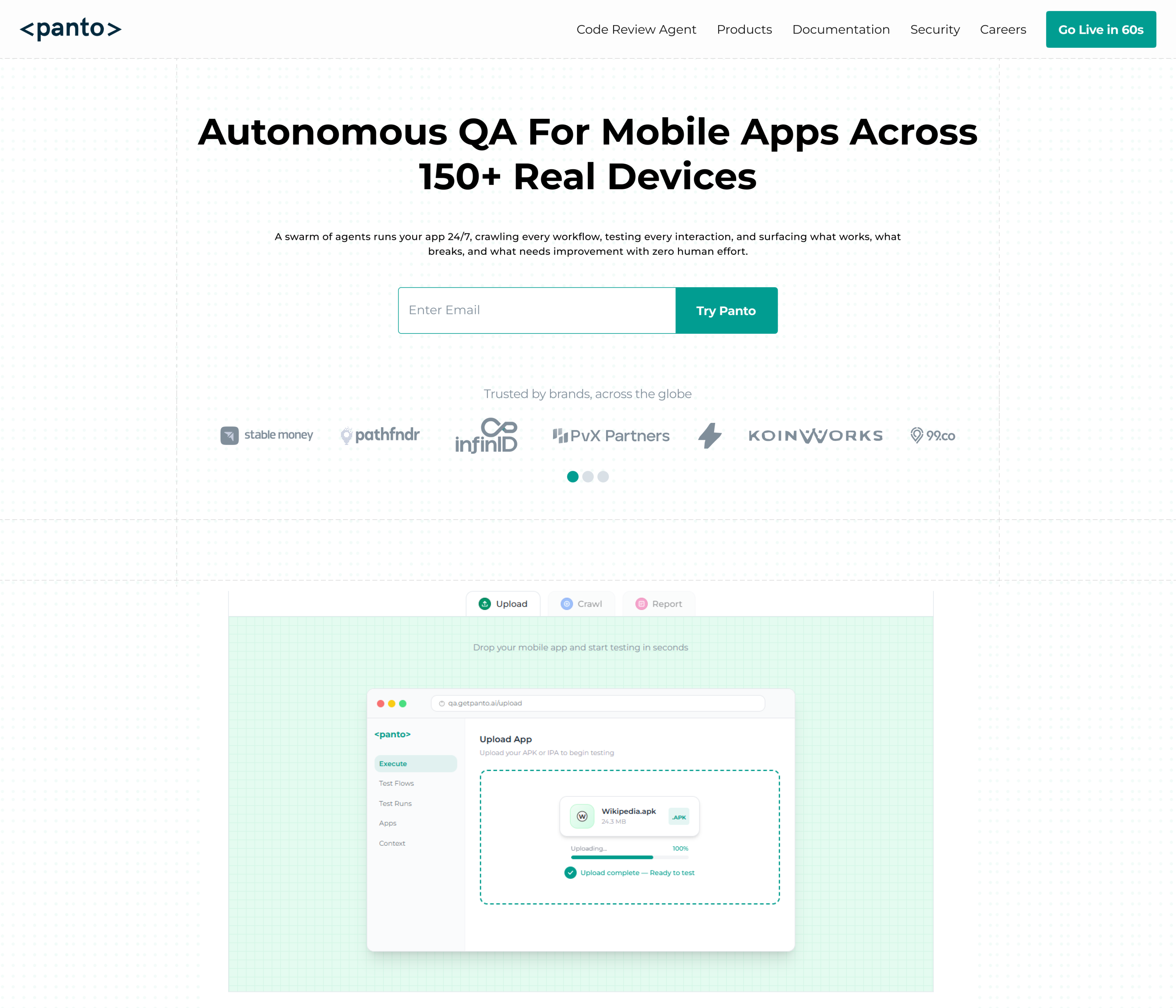
Panto AI is a strong alternative for teams that want testing to feel more AI-native and less script-heavy. Its platform uses machine learning and generative models to create resilient tests, triage failures with human-readable summaries, and auto-heal brittle selectors.
It also describes an agentic mobile QA engine that understands UI intent through visual analysis, structured UI data, and contextual reasoning.
That makes Panto AI especially attractive for teams that want faster test creation and less ongoing maintenance. It is best suited for QA teams, product teams, and engineering orgs that want to reduce flaky automation work while keeping test outcomes understandable and actionable.
Features
- Self-healing automation for brittle selectors and UI changes.
- Human-readable failure summaries for faster triage.
- Natural-language, agentic mobile QA capabilities.
Limitations
- More AI-driven than a traditional pure device-cloud stack.
- Teams that only want simple browser-grid execution may not need its full feature set. This is an inference from its AI-first positioning.
Best Suited For
- Mobile QA teams that want to cut maintenance.
- Teams that value readable failure diagnostics.
- Organizations adopting AI-first test automation.
2. BrowserStack
BrowserStack is one of the most established alternatives because it offers access to thousands of real browsers and devices across web and mobile testing.
Its homepage highlights instant access to 3000+ browsers and real iOS and Android devices, while its product set includes live manual testing, browser automation, app automation, visual testing, accessibility, low-code automation, test management, and a custom device lab.
That breadth is its biggest advantage and also its main tradeoff. It is best for teams that need broad coverage across web and mobile, especially when manual testing, automation, and visual checks all need to live in one platform.
Features
- 3000+ browsers plus real iOS and Android devices.
- Real-device cloud with 20,000+ devices.
- Low-code automation, accessibility, visual testing, and test management.
Limitations
- Its large feature set can feel broad for small teams. This is an inference from the product lineup.
- Teams focused only on mobile app QA may not need the full cross-browser suite. This is an inference from the platform scope.
Best Suited For
- Web and mobile teams with high coverage needs.
- Enterprises that want one platform for multiple testing modes.
- Teams that test real-device features like OTP, media injection, and physical SIM workflows.
3. LambdaTest
LambdaTest, now branded as TestMu AI, is a strong cloud alternative for teams that want AI-native execution across web and mobile. Its official site emphasizes an AI-agentic cloud platform, and its cloud testing pages highlight support for Selenium, Cypress, Appium, and JavaScript with parallel testing for broader device and browser coverage.
This makes it a practical choice for teams already invested in common automation frameworks. The main limitation is that it is a general cloud testing platform rather than a mobile-only specialist, so it fits best when your testing needs span both web and mobile.
Features
- AI-native cloud for testing and quality engineering.
- Selenium, Cypress, Appium, and JavaScript support.
- Parallel execution across browsers and devices.
Limitations
- Less mobile-specialized than dedicated mobile-first platforms. This is an inference from the broader product scope.
- Teams wanting only device-lab workflows may find it broader than necessary. This is an inference from its cloud-first positioning.
Best Suited For
- Teams with mixed web and mobile automation.
- Groups that already use Selenium, Cypress, or Appium.
- QA teams that want cloud parallelization.
4. Sauce Labs

Sauce Labs is a heavyweight enterprise alternative centered on real-device testing. Its real-device cloud pages emphasize access to a very large range of Android and iOS devices, real-world validation, and deep mobile diagnostic signals. The platform also describes itself as AI-ready infrastructure for releasing mobile apps faster and with more confidence.
This makes Sauce Labs especially useful for large teams running high-volume mobile testing with a need for reliability, diagnostics, and scale. The tradeoff is that it is more enterprise-oriented than lightweight point solutions, so smaller teams may find it more than they need.
Features
- Extensive Android and iOS real-device coverage.
- Biometric, GPS, gesture, camera, and sensor support.
- Strong mobile diagnostic signals.
Limitations
- Enterprise depth can be heavier than smaller teams require. This is an inference from the platform positioning.
- It is strongest where mobile scale and diagnostics matter most. This is an inference from the product messaging.
Best Suited For
- Large QA organizations.
- Teams that need real-device validation under real-world conditions.
- Mobile apps where diagnostics are critical.
5. Kobiton

Kobiton is a mobile-first alternative that focuses on real-device testing and delivery. Its site emphasizes mobile testing acceleration, device cloud workflows, and AI-augmented testing, making it a natural choice for teams whose quality process is centered on Android and iOS app delivery.
Because of that focus, Kobiton is a good fit for mobile teams that want device realism and efficient mobile workflows without paying for a broader cross-platform testing suite. It is less compelling for teams that need a full web-plus-mobile quality platform.
Features
- Real-device cloud for mobile testing.
- Device lab management.
- AI-augmented testing and CI/CD support.
Limitations
- More mobile-centric than web-centric. This is an inference from the product scope.
- Less suited to teams that need a broad enterprise QA platform. This is an inference from the mobile-first positioning.
Best Suited For
- Mobile product teams.
- QA teams that want real-device workflows.
- Teams running mobile CI/CD.
6. HeadSpin
HeadSpin stands out when performance matters as much as correctness. Its materials emphasize real devices, real networks, and more than 130 performance KPIs, along with observability that helps teams understand app, device, and network behavior together. That makes it especially relevant for mobile QA programs that want deeper experience data.
It is best for teams that need to go beyond pass/fail testing and diagnose user experience issues across locations, networks, and devices. The tradeoff is that its value is highest when performance and observability are part of the buying decision.
Features
- 130+ performance KPIs.
- Real-device and real-network testing.
- Observability and root-cause style performance insight.
Limitations
- Best value appears when performance analytics are important. This is an inference from the platform focus.
- Teams needing only straightforward UI automation may find it broader than required. This is an inference from the observability-heavy messaging.
Best Suited For
- Performance-driven mobile QA teams.
- Organizations validating global user experience.
- Teams that need device, app, and network visibility together.
7. Perfecto
Perfecto is a strong enterprise alternative that unifies creation, execution, visual validation, devices, and AI analysis. Its official pages also highlight plain-English functional testing, support for Selenium, Appium, Jenkins, and major IDEs, plus easy script migration. That makes it attractive for teams modernizing existing automation without starting from scratch.
The main tradeoff is that Perfecto is built as a comprehensive platform, so it suits teams that need enterprise workflow control rather than a narrow point solution. Best for organizations that want both script-based and codeless testing across web, mobile, and desktop.
Features
- Unified creation, execution, visual validation, devices, and AI analysis.
- Plain-English test creation.
- Support for Selenium, Appium, and Jenkins.
Limitations
- Can feel platform-heavy for smaller teams. This is an inference from its enterprise scope.
- Best when you need migration and governance as much as execution. This is an inference from the feature set.
Best Suited For
- Enterprise QA teams.
- Teams migrating older Appium or script-based suites.
- Organizations that want visual validation plus AI analysis.
8. Functionize

Functionize is a QA platform, built around agentic AI that can build, run, diagnose, and self-heal tests with minimal human input. Its site also emphasizes 99.97% element recognition accuracy and claims that tests can be created far faster than traditional scripting approaches. That makes it one of the most AI-forward options in this list.
It is especially useful for teams trying to reduce brittle maintenance and speed up test creation. The limitation is that it is not positioned primarily as a device cloud, so teams looking for a TestGrid-like real-device execution model may need to evaluate whether the platform matches their workflow.
Features
- Agentic AI that builds, runs, diagnoses, and self-heals tests.
- High element-recognition accuracy.
- Fast creation for non-technical teams.
Limitations
- Less centered on real-device cloud execution. This is an inference from the product positioning.
- Teams wanting classic grid-style control may prefer a more device-focused alternative. This is an inference from the platform description.
Best Suited For
- Teams that want self-healing automation.
- Non-technical users who need fast test creation.
- Organizations prioritizing lower maintenance overhead.
9. ACCELQ

ACCELQ is a codeless automation platform that spans web, mobile, API, desktop, packages apps, and more. Its site also highlights no-code, no-setup cloud-based mobile automation and codeless API automation with test design, planning, and tracking. That makes it a strong fit for teams that want broader application coverage without heavy scripting.
Its biggest advantage is depth within a no-code model. The limitation is that it is more of an automation platform than a real-device cloud, so it is best when workflow automation and codeless design matter more than device-lab-first testing.
Features
- Codeless automation across web, mobile, API, desktop, and more.
- No-code cloud-based mobile automation.
- Codeless API automation with planning and tracking.
Limitations
- Not primarily a real-device cloud product. This is an inference from the product pages.
- Better suited to automation strategy than device inventory management. This is an inference from the platform scope.
Best Suited For
- Teams that want no-code automation.
- QA groups that cover APIs and mobile together.
- Organizations seeking continuous automation across app types.
10. Katalon

Katalon is a broad AI testing platform that plans, authors, executes, and analyzes quality across web, mobile, API, and desktop. Its docs also describe Katalon Studio as an agentic test automation IDE and support combined testing across multiple application types in one project and execution flow.
That flexibility makes Katalon a strong choice for mixed-skill QA teams that want one platform for many surfaces. Its breadth is also the downside, since teams that want only a narrow mobile-device solution may need more configuration than a specialized tool.
Features
- AI platform for web, mobile, API, and desktop.
- Natural-language AI assistant and requirement analysis.
- Combined application types in one project and execution flow.
Limitations
- Broad platform scope can require more setup. This is an inference from its multi-product architecture.
- Mobile-only teams may not need the full stack. This is an inference from the broad application coverage.
Best Suited For
- Mixed-skill QA teams.
- Teams testing web, mobile, API, and desktop together.
- Organizations that want AI-assisted quality workflows.
When To Choose Which TestGrid Alternative
The best TestGrid alternative depends on what problem you are trying to solve. Some teams want AI-generated tests and self-healing automation, while others prioritize real-device coverage, enterprise governance, or codeless test creation.
Use the guide below to quickly identify which platform aligns best with your testing strategy and team structure.
Choose Panto AI If You Want AI-First Test Automation
Pick Panto AI if your biggest challenge is maintaining brittle automation and spending too much time debugging failures. It is ideal for teams that want natural-language test creation, self-healing scripts, deterministic execution, and human-readable failure summaries.
This is the best choice for startups and fast-moving product teams that want to ship mobile apps faster without expanding their QA headcount.
Choose BrowserStack If You Need The Largest Device And Browser Coverage
BrowserStack is the right choice when broad compatibility testing is your top priority. It offers thousands of real devices and browsers, along with visual testing, accessibility checks, and test management.
Choose BrowserStack if you support many device combinations and want a mature, enterprise-ready testing platform.
Choose LambdaTest If You Want A Cloud-Native Testing Platform
LambdaTest is well suited for teams already using Selenium, Cypress, or Appium and looking for scalable parallel execution in the cloud.
It is a strong option for organizations that need web and mobile automation with AI-assisted capabilities at competitive pricing.
Choose Sauce Labs If You Need Enterprise-Scale Mobile Testing
Sauce Labs is best for large organizations with strict security requirements and complex release pipelines.
Its extensive device cloud and advanced diagnostics make it a strong fit for enterprises running large regression suites across distributed teams.
Choose Kobiton If Mobile Testing Is Your Main Focus
Kobiton is purpose-built for Android and iOS application testing, with real-device access and device lab management.
Choose Kobiton if your team is centered on mobile app delivery and wants practical, mobile-specific workflows.
Choose HeadSpin If Performance Testing Matters As Much As Functional Testing
HeadSpin combines real-device testing with deep performance analytics and user experience metrics.
It is ideal for teams that need visibility into network behavior, responsiveness, and real-world app performance.
Choose Perfecto If You Need Governance And Script Migration
Perfecto is particularly useful for enterprises modernizing existing Selenium and Appium frameworks.
Choose Perfecto if you want visual validation, AI analysis, and enterprise-level governance features.
Choose Functionize If You Want Maximum Self-Healing And Low Maintenance
Functionize is designed to minimize manual effort by using agentic AI to build and maintain tests automatically.
It is best for organizations that want to reduce automation maintenance and enable less technical users to contribute.
Choose ACCELQ If You Prefer Codeless End-To-End Automation
ACCELQ is an excellent fit for teams that want to automate web, mobile, and API testing without writing code.
Choose ACCELQ if business users and QA teams need to collaborate on automation in a no-code environment.
Choose Katalon If You Want An All-In-One Testing Platform
Katalon offers web, mobile, API, and desktop testing along with AI-assisted capabilities and flexible coding options.
It is best for mixed-skill teams that want one platform to standardize quality processes across multiple application types.
Quick Recommendation Summary
- Best Overall AI-First Platform: Panto AI
- Best For Device Coverage: BrowserStack
- Best Cloud-Native Alternative: LambdaTest
- Best For Large Enterprises: Sauce Labs
- Best Mobile-Only Platform: Kobiton
- Best For Performance Testing: HeadSpin
- Best For Governance And Migration: Perfecto
- Best For Self-Healing Automation: Functionize
- Best Codeless Platform: ACCELQ
- Best All-In-One Platform: Katalon
Conclusion
Choosing the right TestGrid alternative depends on your team’s priorities, technical requirements, and testing maturity. Some platforms focus on AI-powered test creation and self-healing automation, while others excel in real-device coverage, enterprise governance, codeless workflows, or performance monitoring.
The best approach is to evaluate each tool based on the factors that matter most to your organization, such as ease of use, scalability, framework support, and maintenance effort. Whether you are a startup looking to automate faster or an enterprise managing complex release cycles, the tools in this list offer strong alternatives to TestGrid for a wide range of testing needs.

