Playwright is a modern end-to-end web testing framework that offers fast, cross-browser automation with built-in features like auto-wait and trace viewing. MCP (Model Context Protocol) adds an AI-driven reasoning layer on top of Playwright. In this combination, Playwright handles the actual browser execution, while MCP enables context-driven decision-making.
In practice, MCP is not a testing tool itself but a “context bridge” that lets AI models connect to external systems (Playwright, Jira, APIs, etc.), understand the application’s state, and plan actions before execution. Together, they can form nearly autonomous QA tools: the human (or a Jira ticket) provides a goal in plain English, the MCP agent reasons out an action plan, and Playwright deterministically carries it out.
Deep Dive: Playwright + MCP Model
PlayWright +MCP model and its advantages

This Playwright+MCP model has several significant advantages for web testing:
- Self-healing locators: MCP can reason about missing or changed UI elements. It can dynamically generate new selectors or skip non-critical steps when elements can’t be found. This makes tests more robust against layout changes.
- Natural-language authoring: Test cases can be written as plain English scenarios or Jira tickets. MCP then translates them into browser actions. For example, a description like “login as admin and check invoice history” is turned into a concrete Playwright scrip. This lowers the barrier so non-developers can author tests.
- Cross-application flows: The MCP agent can coordinate across multiple systems. It can drive the user journey through the web UI, a backend API, and even other tools like Figma or a database, verifying the end-to-end experience.
- Adaptive recovery: If something goes wrong (a popup appears, a step fails, etc.), MCP can decide the next move. It might retry, log extra context, or alter the flow based on the situation. This reduces flaky failures.
- Faster authoring & collaboration: By letting stakeholders use plain-language descriptions, Playwright+MCP enables faster test creation. Non-QA team members (e.g. product managers or developers) can contribute without writing code. This speeds up coverage and reduces the QA bottleneck.
Key Pitfalls in the PlayWright +MCP Model
However, these capabilities come with caveats. The DevAssure blog cautions that Playwright+MCP can become chaotic if misused. Some of the key pitfalls are:
- AI doing the clicking – If you let the AI-powered QA agent generate and execute Playwright steps unchecked, tests can become unpredictable and flaky. For example, allowing MCP to write selectors on the fly (without validation) often produces “ghost clicks” or targets the wrong elements.
- Layer confusion – Mixing reasoning (MCP) and execution (Playwright) in a single layer makes debugging very hard. It’s easy to lose sight of why a test failed if the AI decided a different path mid-test.
- Overuse of reasoning – Running the AI reasoning for every little step can dramatically slow down tests. The blog notes that a 2-minute test can blow up to 10 minutes if MCP is invoked too often. One must carefully choose when to trust AI versus doing a direct click.
- Visual fragility – Relying on AI for visual diffs or screenshots can trigger false alarms on minor UI shifts. Every pixel change can become a “failure” if the AI isn’t tuned, creating more noise than value.
Playwright+MCP Is Web-Centric – Not Mobile-Centric

Importantly, Playwright (and by extension MCP’s browser automation) is fundamentally built for web applications, not native mobile apps. Playwright cannot automate native iOS or Android UI elements. At best it can launch a mobile browser instance. In fact, current Playwright support for mobile is limited: it can emulate popular phones in-browser, and it offers experimental support for Chrome on Android via ADB. But it has no real-device support for native iOS or hybrid apps.
For example, the Codoid automation guide notes: “Playwright is one of the best tools for mobile web testing… However, if you need to test native or hybrid mobile apps, Appium or native testing frameworks are better suited”. In other words, Playwright can help test mobile-responsive websites or Chrome on Android, but it cannot tap on UI buttons inside a native Android app or drive a Swift UI on iPhone. It also explicitly does not support iOS devices (no XCUITest API) due to Apple restrictions. In practice, this means any approach built around Playwright+MCP can only cover the mobile web layer. True end-to-end mobile app QA (native or hybrid) falls outside its scope.
In short: Playwright + MCP cannot solve native mobile testing. It has no built-in way to click on an Android app or handle an iOS app. Any plan to test mobile apps with this stack would quickly hit those limits. Teams would still need a separate solution (like Appium or a native recorder) for mobile, leaving a gap that Playwright+MCP alone cannot fill.
The Broken State of Mobile Test Automation
Mobile app testing is notoriously painful and fragmented. Industry analysts and practitioners agree: most mobile QA processes today are broken. Common scripted tools (Appium, XCUITest, Espresso, etc.) are powerful but fragile and high-maintenance. For example, analysis points out that mobile test suites often suffer from “slow manual testing, complex automation tools, device management issues, and the difficulty of testing many platform combinations”.
Pain Points in Mobile Test Automation

1. Manual testing doesn’t scale.
Hand-testing on phones is slow and laborious. Each manual tester can only cover a few devices and flows. As mobile apps grow more complex and device/OS diversity explodes, manual QA becomes a huge bottleneck. According to analysis, “manual mobile testing is difficult to scale…mobile apps become more complex, device models and OS multiply, and continuous delivery makes manual testing a bottleneck”. Inevitably, human testers miss edge cases and the best-case scenarios, leading to coverage gaps.
2. Scripted frameworks are brittle.
Traditional QA automation tools like Appium or Espresso allow writing actual code tests, but they come with heavy overhead. These frameworks often break with small UI changes, require complex setup, and demand specialized SDET skills. As analysis notes: “Scripted test automation tools are complex and high maintenance…tools like Appium, XCUI, and Espresso…are brittle, complex and not always supported cross-platform”. Every minor UI tweak can cause a cascade of failures, forcing teams to constantly update locators and logic. Maintaining these scripts quickly becomes a “full-time job” that slows releases.
3. Device management headaches.
Mobile QA requires testing on physical devices or emulators. Keeping a fleet of real devices up-to-date is expensive and cumbersome. analysis warns that managing devices (whether in-house or via cloud farms) is “time-consuming and expensive”. There are thousands of Android models (and dozens of iOS versions) in use. Debugging and testing all combinations is essentially impossible. Virtual emulators can help, but they often introduce their own limitations (performance, maintenance, scale limits).
4. Siloed processes and tool sprawl.
Often web and mobile teams use completely different stacks. This leads to duplication of effort and inconsistent approaches. analysis highlights that mobile QA is frequently “specialized and siloed” – separate teams, separate tools, and late discovery of defects. In effect, organizations have one approach for web and a completely different (often disjointed) approach for mobile. This fragmentation wastes resources and delays feedback.
5. Evolving app complexity.
Modern mobile apps blend webviews, native code, cross-platform frameworks (React Native/Flutter), and complex backend interactions. Many mobile apps even mix native screens with embedded web content. Traditional tools struggle to handle these hybrid architectures. For instance, testing webviews is notoriously tricky – the blog notes that “most automated mobile testing tools struggle to effectively test webviews”. In practice, this means QA teams constantly jump between different frameworks or fall back to brittle hacks.
So How Does This Impact Mobile QA?
All of these issues contribute to a broken mobile QA landscape. Tests take too long to author and fix, coverage is incomplete, and releases are risky. As one Panto analyst summarized: “In short, manual QA is error-prone, resource-heavy, and a bottleneck in modern mobile development”. Coverage gaps and flaky scripts waste engineering time and erode confidence in automation.
Industry thought leaders agree that something new is needed. analysis explicitly argues that QA teams now require “streamlined platforms that unify cloud-based testing, ease of low-code test creation, and the power of AI”. In other words, the future of mobile QA lies in codeless, AI-assisted automation that can scale across devices and adapt on the fly.
Toward a Codeless, AI-Driven Mobile QA – Enter Panto AI QA
To address these challenges, the market is shifting toward codeless and AI-powered mobile testing platforms. These aim to let non-developers build tests quickly and to make tests self-maintaining. A next-generation entrant is Panto AI QA, a purpose-built platform for mobile app testing. Panto positions itself as a “next-generation mobile app testing platform aka Vibe Debugging Platform” that uses an AI agent to navigate apps and generate tests automatically. Here’s how Panto tackles the broken mobile QA problem:

1. AI-Driven Test Generation
Panto’s core is an intelligent AI agent. The agent can interpret plain-language instructions or high-level scenarios (similar to how MCP does) and turn them into detailed test flows. According to Panto, it “revolutionizes mobile test automation” by letting teams build full test suites “without writing complex test scripts”. Under the hood, Panto’s AI analyzes the app’s behavior and interface (using computer vision and NLP) to map out screens and actions. It can then generate an initial test plan or script automatically. This dramatically speeds up authoring – testers don’t have to hand-code every step. The AI “gets under the hood” to understand the app’s structure and proposes self-healing test scenarios by itself.
2. No-Code / Codeless Authoring
Panto provides an intuitive visual interface and supports natural-language inputs, effectively making it a no-code/low-code automation tool. Testers and even product managers can define flows by clicking through the app or by writing simple English instructions, instead of coding. This democratizes test creation. As Panto’s docs state, testers can “build comprehensive test suites without writing complex test scripts”. In practice, this means a QA engineer can describe a scenario (e.g. “login as user, add items to cart, check out”) and the platform translates it into an executable test. This approach aligns with the industry trend toward codeless test automation tools, so teams with less coding expertise can still contribute.
3. Native & Cross-Platform Support
Panto is designed specifically for mobile-first applications, including native iOS and Android apps as well as popular cross-platform frameworks like React Native and Flutter. Unlike Playwright (which is web-only), Panto has native hooks to interact with mobile app elements. It can tap buttons, enter text, swipe screens, etc., on real devices. The AI agent is built to handle mobile-specific behaviors (navigation gestures, permissions, etc.) automatically. In effect, it brings the same “agentic QA” approach (AI reasoning over the UI) to the mobile world.
4. Real-Device Execution and Integration
Panto integrates with real-device clouds like BrowserStack and LambdaTest (as well as on-premise device farms). This lets teams execute the AI-generated tests on hundreds of actual devices in parallel. Panto calls this “real-device cloud support”, eliminating the blind spots of emulator-only testing. Results and logs are collected from each device run. Importantly, Panto can also integrate into CI/CD pipelines, so every code change can trigger mobile regression tests across device farms automatically. This bridges the gap between automated test generation and reliable, scalable execution – a key piece that many fractured mobile workflows lack, leading to missed metrics.
5. Deterministic Script Generation
Although Panto is codeless at the user level, it ultimately generates deterministic test scripts that can be reviewed, exported, or run independently. In other words, behind the scenes the AI builds a concrete script. Panto can export these in various formats (e.g. Appium code, Maestro scenarios, or raw test files) that team can store. This provides transparency and auditability – the test isn’t a black box. Teams can also integrate these scripts into other frameworks if needed. (This is crucial for organizations that still require code review or compliance checks of their test logic.) Because Panto’s AI generates consistent scripts, they behave predictably on each run.
6. Self-Healing and Resilience
Following the pattern of Playwright+MCP, Panto embeds self-healing capabilities. When UI elements change or tests fail unexpectedly, Panto’s AI will try to recover. For example, it can search for a moved button, scroll the screen, or apply alternate selectors if the primary one fails. The platform automatically logs the reasoning for these recovery actions for auditing. This greatly reduces test flakiness and maintenance. (Notably, DevAssure’s guidance on MCP emphasizes that AI should mainly be used for recovery scenarios – Panto’s design mirrors this best practice by using AI to adapt tests rather than replacing the entire flow.)
7. Fast Maintenance and Coverage
By combining the above, Panto aims to minimize the upkeep that normally plagues mobile tests. Since the AI continuously learns the app, it can quickly regenerate or adjust tests as the app evolves. This dramatically cuts down the usual 30–40% of time teams spend just updating tests after UI tweaks. The company claims their approach achieves “up to 100% coverage in under two weeks” in some benchmarks, although specific numbers depend on the app. For QA teams, this means faster releases and fewer regressions slipping through.
What Panto Offers
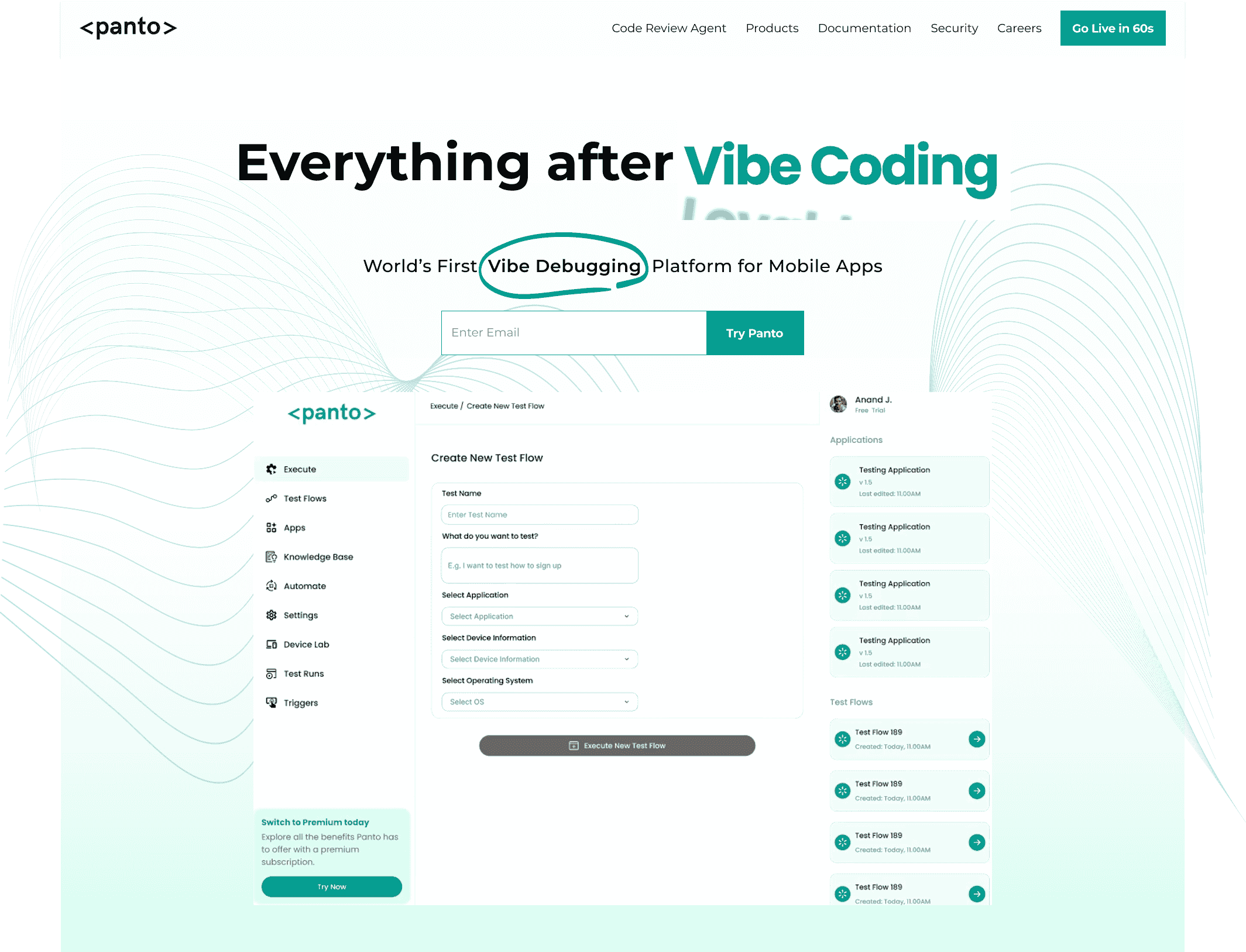
In real terms, Panto positions itself as “the only solution that blends true no-code testing, AI-powered agent execution, and deterministic script generation”. In practice, it delivers a no-code mobile QA experience with an AI agent under the hood. According to its documentation, Panto “enables QA teams to build comprehensive test suites without writing complex test scripts” and provides native support for iOS/Android with AI-managed self-healing.
Overall, Panto aims to address every failure point in mobile QA: it uses AI reasoning like MCP but built natively for apps; it’s codeless like many modern test tools; it runs on real devices for full coverage; and it exports deterministic scripts for reliability. For teams drowning in flaky mobile tests, it represents a new paradigm. By abstracting complexity behind an AI agent and providing a visual, collaborative interface, Panto AI QA could make mobile testing scalable, maintainable, and future-ready – in stark contrast to the current “brittle and broken” status quo].
Conclusion
Playwright combined with MCP brings exciting advances to web test automation – dynamic recovery, plain-English tests, and AI reasoning give teams new agility. But this architecture remains squarely web-focused. It does not address the native mobile app problem, where fragmentation and fragility still reign. Mobile QA remains “broken”, beset by slow manual flows and brittle scripts.
The future will require a similarly sophisticated approach for mobile testing: deterministic execution with context-aware reasoning. Panto AI QA is one such solution. By marrying no-code interfaces with an AI testing agent and real-device execution, it promises to overcome today’s mobile QA hurdles. Whether Panto or other AI-driven, codeless platforms ultimately deliver on this promise remains to be seen. But one thing is clear: as software goes mobile-first, test automation must evolve beyond traditional debugging. Codeless, AI-powered mobile testing tools like Panto represent the next step in that evolution – providing both the speed of automation and the intelligence to adapt, without the chaos.