
Continuous Integration (CI) pipelines are built to deliver deterministic feedback: a failed build should indicate a real regression, and a passing build should signal stability.
Flaky tests violate that contract. By introducing non-deterministic failures, they erode trust in the pipeline and force teams to question every red build.
Over time, engineers rerun jobs “just to check,” real defects get dismissed as noise, and delivery velocity slows. CI shifts from a reliable quality gate to a probabilistic system.
Detecting flaky tests automatically is not just optimization, it is restoring signal integrity at scale.
Flaky Tests: A Deep Dive
What Makes a Test Flaky?
A flaky test is often defined as a test that “sometimes passes and sometimes fails.” That description is directionally correct but operationally insufficient.
From a systems perspective, a flaky test is: A test exhibiting stochastic failure behavior under equivalent code and environmental conditions.
This non-determinism typically arises from:
- Timing dependencies (race conditions, asynchronous waits)
- Shared state contamination
- Order-dependent execution
- External service variability
- Resource contention in CI runners
- Environment configuration drift
Deterministic tests produce consistent outcomes for identical inputs. Flaky tests introduce entropy into the pipeline. Over time, that entropy accumulates.
Why Manual Identification Fails at Scale
Many teams attempt to detect flaky tests manually. The process usually looks like this:
- A test fails.
- A developer reruns the job.
- The test passes.
- The failure is dismissed as “probably flaky.”
This approach fails for several reasons:
1. Rerun Bias
Reruns mask the true failure distribution. Teams see only the most recent run, not historical volatility.
2. Confirmation Bias
Developers expect some failures to be flaky and subconsciously classify ambiguous failures as noise.
3. Log Fatigue
Large pipelines produce massive logs. Manual triage becomes cognitively expensive.
4. Hidden Cost Accumulation
Each rerun consumes compute resources, extends feedback cycles, and increases operational cost.
At scale — across hundreds of tests and thousands of pipeline runs — manual detection is statistically unreliable. Flaky test detection must become data-driven.
Core Data Signals for Automatic Flaky Test Detection
Effective flaky detection systems analyze historical CI metadata rather than relying on single-run behavior.
Below are the primary signal categories used in automated detection frameworks.
1. Historical Pass/Fail Variance Analysis
The foundational method involves analyzing failure rate volatility over time.
If a test has:
- A 0% failure rate → likely stable
- A 100% failure rate → likely broken
- A 10–40% inconsistent failure rate → potential flake candidate
However, raw percentages are insufficient.
More robust approaches include:
- Moving averages across N builds
- Failure rate confidence intervals
- Standard deviation of outcomes
- Control chart modeling (Statistical Process Control)
Using binomial probability modeling, teams can compute the likelihood that observed failures are due to randomness versus systemic regression.
For example:
If a test fails 3 out of 20 runs without associated code changes, the probability distribution suggests instability rather than deterministic failure.
This statistical framing dramatically reduces misclassification.
2. Retry Pattern Detection
Retry patterns provide one of the strongest flakiness indicators.
Common signature:
- Initial failure → immediate pass on rerun
Detection signals include:
- Conditional probability: P(pass | prior failure)
- Frequency of fail-pass transitions
- Retry dependency ratios
If a test fails but passes upon rerun more than 70–80% of the time, it demonstrates probabilistic instability.
Tracking retry patterns at scale reveals tests that artificially inflate pipeline instability metrics.
3. Cross-Branch Instability Correlation
A deterministic regression should correlate with code changes.
Flaky tests often:
- Fail across unrelated pull requests
- Fail on branches with no relevant diffs
- Trigger in code areas untouched by recent commits
By correlating failures with version control metadata, detection systems can compute:
- Failure-code proximity scores
- Diff-aware instability probabilities
When failures occur without meaningful code deltas, flakiness probability increases.
4. Execution Duration Variance
Flaky tests often exhibit runtime instability before functional failure appears.
Signals include:
- High runtime variance
- Outlier execution times
- Gradual timing drift
- Timeout boundary proximity
Runtime volatility frequently indicates:
- Resource contention
- Network dependency instability
- Inefficient waits
- Asynchronous race conditions
Tracking execution variance can detect emerging flakiness before outright failures spike.
5. Environment-Specific Failure Clustering
Some tests fail only on:
- Specific CI runners
- Certain operating systems
- Particular container configurations
- High-load parallel execution contexts
Clustering failures by environment reveals non-deterministic environmental dependencies.
Detection systems should tag failures with infrastructure metadata to isolate environmental flakiness.
Statistical Models for Flaky Test Detection
High-maturity teams move beyond threshold heuristics into statistical modeling.
1. Binomial Distribution Modeling
Tests are binary events (pass/fail). The binomial model allows teams to:
- Estimate expected failure probability
- Calculate confidence intervals
- Determine statistical significance of observed variance
This prevents overreacting to small sample sizes.
2. Bayesian Inference
Bayesian models update flakiness probability as new data arrives.
Advantages:
- Continuous probability refinement
- Reduced sensitivity to short-term anomalies
- Better classification confidence scoring
This is particularly useful in dynamic CI environments.
3. Control Charts (SPC)
Statistical Process Control charts help detect abnormal variation patterns.
If failure frequency crosses control thresholds, instability is statistically significant rather than random.
4. Anomaly Detection Models
Unsupervised learning techniques can detect:
- Sudden failure rate shifts
- Runtime pattern anomalies
- Behavioral divergence from historical norms
These methods are effective in large pipelines with thousands of tests.
Heuristic vs Machine Learning Approaches
1. Heuristic-Based Detection
Rule-driven logic such as:
- Failure rate > X% and < Y%
- Fail → pass on retry frequency
- Runtime variance above threshold
- No recent code change correlation
Advantages:
- Transparent logic
- Easy implementation
- Lower computational complexity
Limitations:
- Static thresholds
- Less adaptive to pipeline growth
2. Machine Learning-Based Detection
ML approaches extract features such as:
- Historical failure sequences
- Log embeddings
- Runtime vectors
- Environmental metadata
- Code change proximity metrics
Classification models (e.g., gradient boosting, logistic regression) can score flakiness probability dynamically.
Benefits:
- Adaptive learning
- Multivariate analysis
- Higher detection precision
Trade-offs:
- Infrastructure complexity
- Need for labeled data
- Model monitoring requirements
In enterprise CI environments, hybrid approaches often yield optimal results.
Differentiating Flaky Tests from Real Regressions
One of the most dangerous outcomes in automated testing is misclassification. Labeling a true regression as a flaky test can allow defects into production. Conversely, treating flakiness as a regression wastes engineering cycles.
Robust classification requires multi-signal validation across code, environment, and execution context.
Below are the core analytical mechanisms high-maturity teams implement.
Code Change Proximity Analysis
A deterministic regression should correlate with a meaningful code delta.
To evaluate this, detection systems compute proximity between:
- The failing test
- Modified source files
- Recent dependency updates
- Configuration changes
Techniques include:
- Mapping test coverage to modified files
- Git diff analysis at file and function granularity
- Dependency graph traversal
- Historical failure correlation with similar diffs
If a test fails immediately following changes to code it exercises — particularly within its dependency tree — regression probability increases.
Conversely, if:
- The failure occurs across unrelated pull requests
- No relevant files were modified
- The same failure signature appeared in prior builds without code change
Then flakiness probability increases.
More advanced systems compute a failure-code affinity score, quantifying how tightly a failure aligns with the modified surface area. Low affinity suggests instability rather than deterministic breakage.
Isolation Re-Execution
Parallel CI execution introduces shared resource contention, race conditions, and hidden ordering dependencies.
To differentiate flakiness from regression, systems can perform controlled re-execution:
- Run the failing test alone.
- Execute in a fresh, isolated environment.
- Disable parallelization.
- Reset database or state dependencies.
If the failure disappears under isolation, it indicates:
- Shared state coupling
- Timing sensitivity
- Infrastructure contention
- Order dependency
If the failure persists in isolation, regression likelihood increases.
Isolation re-execution is particularly powerful when paired with runtime telemetry (CPU, memory, network I/O). If instability correlates with resource saturation rather than code change, classification confidence improves.
Deterministic Replay
A regression should be reproducible under equivalent conditions.
Deterministic replay mechanisms attempt to recreate:
- Identical container image
- Same dependency versions
- Same environment variables
- Same test seed values
- Same commit SHA
If the failure reproduces consistently in this controlled replay, it behaves deterministically.
If reproduction attempts yield inconsistent outcomes under identical configuration, stochastic behavior is present.
Advanced setups log:
- Random seeds
- Thread scheduling metadata
- API response timing
- Mock invocation sequences
This enables forensic replay analysis, reducing ambiguity in classification.
The key principle: Deterministic defects reproduce reliably. Flaky defects resist consistent reproduction.
Cross-Test Contamination Analysis
Some failures are not isolated to a single test but are triggered by preceding execution context.
Symptoms include:
- Test passes when run alone
- Fails when run after specific other tests
- Order-dependent failure patterns
- Database state leakage
- Residual global variables
To detect contamination:
- Randomize execution order
- Execute suspect test at different suite positions
- Track inter-test state mutation
- Monitor shared resource access patterns
If failure probability shifts significantly depending on execution order, the issue likely stems from shared state or improper teardown, which are classic flakiness patterns.
Statistical modeling can quantify order sensitivity by measuring outcome variance across multiple randomized suite executions.
Temporal Pattern Analysis
Another differentiator between regression and flakiness is failure timing behavior.
Regressions tend to exhibit:
- Immediate and persistent failure after a specific commit
- Stable failure rate near 100%
Flaky tests tend to exhibit:
- Intermittent bursts of failure
- Long stable periods followed by sporadic spikes
- Correlation with CI load peaks
By analyzing time-series failure density, detection systems can classify:
- Persistent structural failure (regression)
- Episodic instability (flake)
- Load-correlated failures (environmental flake)
Time-series modeling (moving averages, anomaly thresholds) significantly increases classification reliability.
Failure Signature Consistency
Regression failures typically produce consistent stack traces in CI pipelines and error messages.
Flaky tests often generate:
- Variable stack traces
- Different timeout durations
- Inconsistent assertion boundaries
- Environment-dependent error messages
Clustering failure logs using signature similarity scoring helps distinguish:
- Stable, repeatable defect signatures
- Divergent, unstable failure behavior
Higher signature entropy often correlates with flakiness.
Why Multi-Signal Corroboration Is Essential
Failure rate alone cannot differentiate:
- A rare regression
- An emerging flake
- An environmental anomaly
Reliable classification requires corroboration across:
- Code proximity
- Retry and self-healing behavior
- Runtime variance
- Environment metadata
- Temporal patterns
- Reproduction consistency
- Failure signature similarity
High-confidence classification emerges only when multiple indicators converge.
This probabilistic framing minimizes both false positives (mislabeling regressions) and false negatives (ignoring instability).
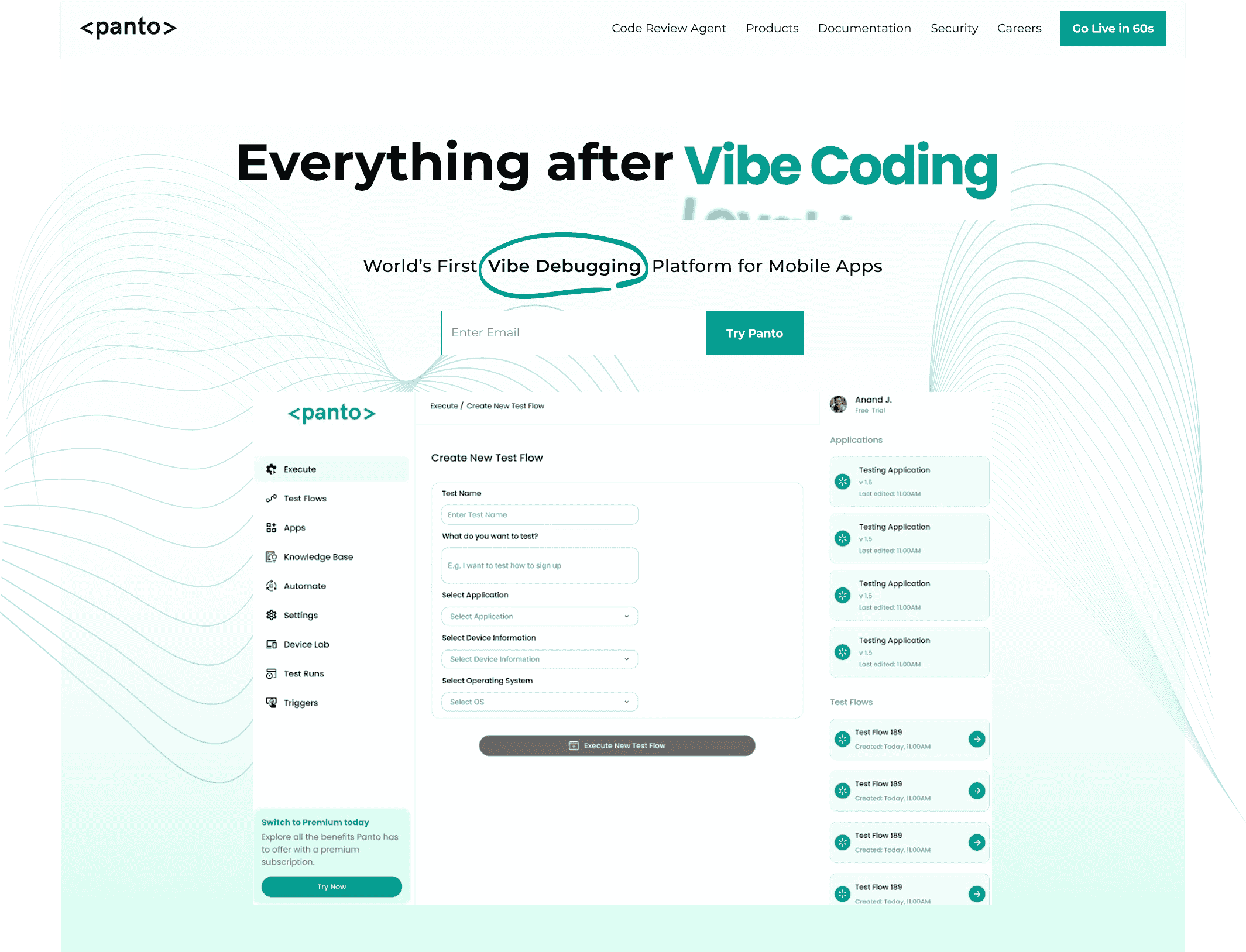
Everything After Vibe Coding
Panto AI helps developers find, explain, and fix bugs faster with AI-assisted QA—reducing downtime and preventing regressions.
- ✓ Explain bugs in natural language
- ✓ Create reproducible test scenarios in minutes
- ✓ Run scripts and track issues with zero AI hallucinations
Building an Automated Flaky Test Detection Pipeline
Automatic flaky detection is not a single algorithm. It is an architectural system layered across CI data, statistical analysis, and feedback workflows.
At scale, this resembles a reliability observability pipeline for test signal integrity.
1. Data Ingestion Layer
The ingestion layer captures every signal emitted by your CI system. Without high-fidelity data, statistical classification becomes unreliable.
Core inputs include:
CI Metadata
- Build ID
- Pipeline ID
- Branch name
- Pull request identifier
- Commit SHA
- Author metadata
- Execution node or runner ID
This contextualizes failures relative to version control and infrastructure.
Test Results
- Pass/fail status per test
- Error messages
- Stack traces
- Exit codes
- Assertion details
Granularity matters. Storing only aggregate suite status eliminates classification precision.
Execution Durations
- Per-test runtime
- Setup/teardown duration
- Queue wait time
- Total job duration
Runtime anomalies frequently precede flake classification. Duration must be tracked longitudinally.
Retry Events
- Number of retries
- Outcome of each retry
- Time between retries
- Manual vs automated rerun triggers
Retry patterns are one of the strongest flakiness indicators. They must be explicitly captured rather than inferred.
Infrastructure Tags
- Operating system
- Container image hash
- Runner type
- CPU/memory allocation
- Geographic region
- Parallelism level
Environmental clustering analysis depends on this metadata. Without it, environmental flakes are misclassified as regressions.
The ingestion layer should stream structured events into a centralized system (e.g., event bus, data warehouse, or observability pipeline). Raw logs alone are insufficient.
2. Historical Storage
Flaky detection is fundamentally a historical pattern recognition problem.
A centralized test history repository should index each test execution by:
- Test identifier (stable ID independent of file renaming)
- Commit SHA
- Branch
- Environment metadata
- Execution timestamp
- Runtime
- Retry count
- Failure signature hash
Key architectural considerations:
- Tests must have stable, canonical identifiers.
- Historical depth should span weeks or months to detect long-term patterns.
- Storage should support time-series queries and aggregation at scale.
This repository becomes the source of truth for:
- Failure volatility trends
- Cross-branch instability
- Recurring flake behavior
- Regression onset detection
Without centralized historical indexing, detection becomes reactive instead of predictive.
3. Signal Extraction Engine
Once data is collected, the system must transform raw CI telemetry into structured signals.
This engine computes derived metrics such as:
Failure Rates
- Rolling failure percentage over N builds
- Branch-specific failure rate
- Environment-specific failure rate
Rolling windows prevent overreacting to isolated anomalies.
Variance Metrics
- Standard deviation of runtime
- Failure frequency volatility
- Time-series drift analysis
High variance often signals instability even when overall failure rate appears low.
Retry Pattern Analysis
- Probability of pass after failure
- Consecutive fail-pass transitions
- Retry dependency ratios
Conditional probability modeling significantly improves flake detection accuracy.
Runtime Deviation
- Z-score for execution time
- Outlier detection
- Timeout boundary proximity
A test consistently running near timeout thresholds has elevated risk.
Code Proximity Metrics
- Overlap between modified files and test coverage
- Dependency graph adjacency
- Historical failure correlation with similar diffs
These signals help distinguish regression from environmental instability.
4. Scoring Layer
The scoring layer synthesizes extracted signals into a probabilistic classification.
Rather than binary labels (“flaky” or “not flaky”), mature systems assign a dynamic flakiness probability score.
Scoring approaches include:
Statistical Models
- Binomial confidence interval analysis
- Bayesian updating of failure probability
- Control chart threshold detection
- Time-series anomaly scoring
These methods quantify uncertainty rather than guess.
Heuristic Rules
Examples:
- Failure rate between 5% and 60%
- Passes on retry more than 75% of the time
- High runtime variance with low code affinity
Heuristics are transparent and easier to implement, but less adaptive.
Machine Learning Classifiers
Feature inputs may include:
- Historical failure vectors
- Retry sequence patterns
- Log embeddings
- Runtime drift metrics
- Environment metadata
- Code proximity scores
Models such as logistic regression, gradient boosting, or ensemble methods can output a calibrated flakiness probability.
ML-based scoring improves classification precision in large, heterogeneous pipelines.
5. Alerting & Feedback Loop
Detection without action does not improve CI reliability. The feedback layer operationalizes classification results.
Key components include:
Flagging High-Probability Flakes
When flakiness probability crosses a defined threshold:
- Annotate pipeline results
- Label tests as “suspected flake”
- Suppress redundant alerts
- Prevent unnecessary reruns
This reduces alert fatigue.
Reliability Dashboards
Surface aggregated metrics represented in a dashboard such as:
- Flake rate trends
- Top unstable tests
- Environment-specific instability
- CI confidence score
- Retry cost impact
Visibility converts detection into accountability.
Quarantine Workflows
High-confidence flaky tests may be:
- Temporarily isolated
- Removed from gating pipelines
- Moved into non-blocking suites
However, quarantine must include tracking mechanisms to prevent silent code quality decay.
Remediation Tracking
Track:
- Mean time to quarantine
- Mean time to fix
- Recurrence rate
- Stability after remediation
This closes the reliability loop and transforms flaky detection from reactive classification into proactive quality governance.
The System Must Be Iterative
An automated flaky detection system is not static infrastructure.
It must:
- Continuously ingest new execution data
- Recalculate probability scores
- Adapt thresholds as pipeline scale evolves
- Incorporate new signal dimensions
- Monitor classification accuracy
As pipelines grow in complexity — with more parallelism, ephemeral environments, and distributed services — the detection system must mature alongside them.
Ultimately, the objective is not merely identifying flaky tests.
It is increasing CI signal confidence over time.
When detection, classification, and remediation operate as a closed loop, CI regains its most valuable property:
Metrics to Track Flaky Test Health
Detection is not the end goal. Signal quality is.
High-maturity teams monitor:
- Flake rate percentage
- Flaky test density per suite
- Retry frequency per build
- CI confidence score
- Mean time to quarantine
- Flake recurrence rate
These metrics reveal whether reliability is improving over time.
Organisational Practices That Reduce Flakiness
Automation detects instability — but prevention requires discipline.
Effective practices include:
- Enforcing test isolation
- Deterministic data seeding
- Ephemeral test environments
- Strict mocking boundaries
- Eliminating shared global state
- Governing parallel execution strategies
- Observability instrumentation within tests
Cultural reinforcement is critical. Flaky tests must be treated as quality debt, not tolerated as background noise.
The Broader Reliability Context
Flaky test detection should not exist in isolation.
It connects directly to:
- CI runtime optimization
- Failure signal quality assurance
- Deployment confidence
- Engineering velocity
- Infrastructure observability
When detection is automated and statistically grounded, teams stop rerunning pipelines blindly. Instead, they respond to high-confidence failure signals.
That restores CI’s original purpose: deterministic feedback.
Conclusion: Flakiness Is a Signal Integrity Problem
The objective is not simply to reduce red builds. It is to ensure that when a pipeline fails, engineers trust the failure.
Automatic flaky test detection transforms CI from a probabilistic system into a statistically governed one.
By leveraging historical data, modeling variance, correlating with code changes, and scoring instability, organizations can restore signal reliability at scale.
In high-velocity engineering environments, trust in CI is a competitive advantage.

