Just weeks after AWS disclosed a major DynamoDB outage in late October 2025 (triggered by a latent DNS-management race condition), Cloudflare suffered its own large-scale outage on November 18, 2025. Both incidents underscore how fragile modern cloud systems can become when small bugs combine with high deployment velocity.
Some experts have dubbed today’s fast, AI-assisted “vibe coding” culture, which emphasizes shipping new features quickly as trading away robustness for speed. The Cloudflare outage postmortem makes this clear: a seemingly innocuous database permission change cascaded into a network-wide failure.
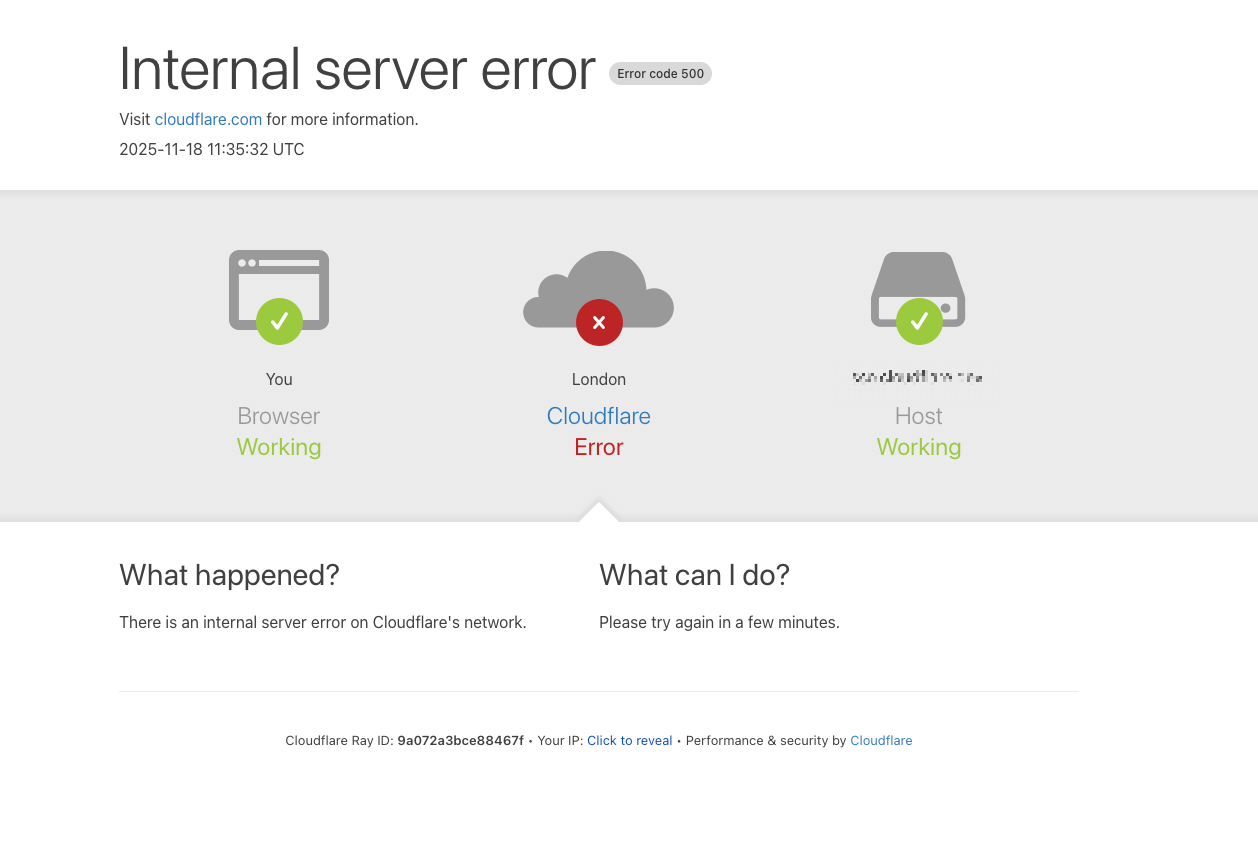
Cloudflare’s report confirms no malicious attack was involved. Instead, on Nov 18 at 11:20 UTC, our network began seeing “significant failures to deliver core network traffic,” with users getting the above error.
The culprit was a database change: a ClickHouse permission update at 11:05 caused the Bot Management feature-file query to double its output (via duplicate rows). That oversized file violated an internal 200-feature limit (set for performance), causing a Rust “unwrap” panic in Cloudflare’s new FL2 proxy code and triggering HTTP 5xx errors across the CDN.
Cloudflare Outage Timeline and Sequence of Events
Key events unfolded as follows:
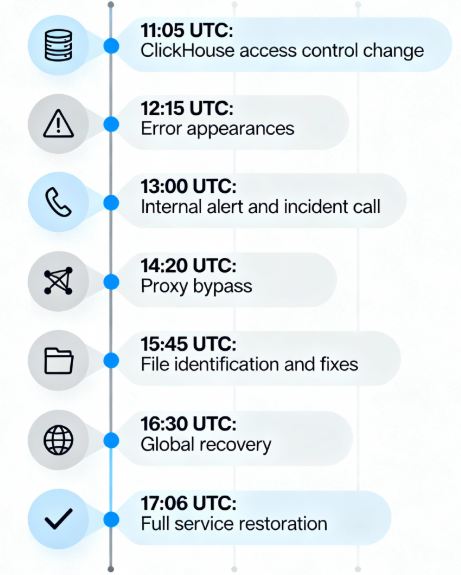
- 11:05 UTC – Cloudflare deploys a ClickHouse access control change to expose underlying shard metadata.
- 11:28 – The first errors appear on customer HTTP traffic as the new Bot Management feature file starts propagating. (Earlier, system metrics were normal.)
- 11:31–11:35 – An internal monitoring test triggers an alert at ~11:31, and an incident call is convened by 11:35. Engineers initially see degraded response rates in Workers KV and attempt mitigations (rate limiting, traffic shaping).
- 13:05 – To reduce pressure, Teams bypass the core proxy for Workers KV and Access, falling back to an older proxy version. This lessens the downstream impact (the bug was still present, but older code masked it).
- 13:37 – The Bot Management configuration file is identified as the trigger. Multiple workstreams begin. The fastest path: restore the last-known-good version of the file.
- 14:24 – New (bad) feature-file generation is halted. A tested, correct feature file is manually pushed out to all nodes.
- 14:30 – Core services begin recovering. A correct Bot Management file is deployed globally; HTTP 5xx error rates drop sharply. (Cloudflare reports “core traffic was largely flowing as normal by 14:30″.)
- By 17:06 – All remaining systems have been restarted or recovered, and traffic returns to normal levels. (The long tail on the errors chart reflects final service restarts.)
This timeline shows the unusual “zig-zag” spike in errors every ~5 minutes as good and bad feature files alternated. Eventually the bad file prevailed and errors stabilized until remediation took effect.
Deep Dive into the CloudFlare Outage
Root Cause: Bot-Management Feature File and Query Bug
Cloudflare’s Bot Management module embeds a reinforcement-learning model that scores each request as bot or human. This ML model consumes a “feature” configuration file (a list of request-trait parameters). The feature file is regenerated every few minutes via a ClickHouse query so that it stays up-to-date.
On Nov 18, the scheduled ClickHouse update at 11:05 changed query semantics: it granted explicit access to underlying shard tables in the r0 schema. In prior behavior, querying metadata returned only the default schema’s columns by assumption; after the change, the same query now returned columns from r0 too.
In practice, the Bot feature-generation query (a system.columns lookup) suddenly returned all columns from both default and r0 tables. Concretely, the report notes that “the response now contained all the metadata of the r0 schema, effectively more than doubling the rows” in the resulting feature file.
In other words, a permission tweak caused duplicate feature entries. The new feature file exceeded Cloudflare’s built-in limit of 200 features. As soon as the bloated file hit production (in the FL2 proxy code path), the proxy panicked:
thread fl2_worker_thread panicked: called Result::unwrap() on an Err valueThis unhandled Rust panic (during feature-file parsing) turned into HTTP 500 errors for any request going through the bot-management path. In summary, a simple DB query change made the ML feature config file twice as large, which triggered an internal error and caused core requests to fail.
Failure Propagation and Impact Across Systems
Once the error occurred, it rippled through most Cloudflare services that depended on the core proxy or bot logic. The effect on customers varied depending on their proxy version: Cloudflare was midway through migrating traffic to a new proxy engine (FL2).
Per the report, customers on FL2 all saw 5xx errors, while customers still on the legacy proxy (FL) saw no crashes – but all bot scores defaulted to zero. This meant any customer using bot scores to block bots would suddenly drop all traffic (false positives). In short:
- Core CDN and Security: Returned HTTP 5xx to requests (customers saw error pages like the one above).
- Turnstile (CAPTCHA): Failed to load entirely, so new logins to the dashboard were blocked.
- Workers KV: Front-end gateway saw a surge of HTTP 5xx errors as its proxy calls failed.
- Dashboard: Mostly up, but users couldn’t log in (Turnstile was down on the login page).
- Access (Zero Trust Auth): Widespread authentication failures from the start of the incident until rollback, meaning users got errors instead of reaching protected apps. (Existing sessions were unaffected, but no new logins succeeded.)
- Email Security: Largely unaffected; a minor reputation feed went offline briefly but did not critically impact customers.
In addition, Cloudflare saw unusually high CPU use on proxy nodes as its error-debugging systems kicked in, which added latency for surviving traffic. At one point, even the Cloudflare status page (hosted outside Cloudflare’s network) went down by coincidence, initially confusing the team into thinking this might be an external attack. In short, the bug turned into a cascading failure – flipping core traffic offline and then affecting most dependent control-plane services until fixed.
Incident Diagnostics and Mitigation
Initially, the errors looked like an external event (the status page outage and high error volumes spooked the team). However, internal telemetry soon pointed to an internal config issue. An automated test at ~11:31 picked up the anomaly, and by 11:35 an incident was declared. Early mitigation attempts included traffic shaping and account limiting on Workers KV to reduce load. Within about an hour, engineers used knowledge of Cloudflare’s architecture to narrow the cause: the Bot Management module’s feature file was the trigger.
To blunt the impact while debugging, at 13:05 the team bypassed the core proxy for Workers KV and Access, sending them through an older proxy build. This reduced error rates (since the FL engine simply dropped features instead of crashing). With that reprieve, engineers focused on restoring the bot-config file. By 13:37 they had confirmed the feature-file bug was the culprit and set out to roll back to a known-good version. A parallel workstream halted further bad file generation and propagated the last working file.
By 14:24, the team had stopped new feature-file deployments altogether and tested the rollback: as promised, the old file cured the errors in FL2. With confidence, they globally pushed the good file and restarted the proxy at 14:30. The core proxy was then largely stable: 5xx rates fell back to baseline and most traffic flowed normally. It took until ~17:06 for all lingering effects (restarting any services still in a bad state) to clear up.
Lessons Learned and Future Protections
Cloudflare’s Leadership Response and Architectural Hardening
Cloudflare’s leaders stress that this Cloudflare outage “is unacceptable” and the worst Cloudflare outage since 2019. They have outlined several architectural hardening steps: treating internally generated config files like external input (with validation checks), adding global kill-switches to disable new features, preventing diagnostic logs or core dumps from choking resources, and systematically reviewing failure modes in all proxy modules.
In essence, every control plane and configuration path will need stronger guardrails. Cloudflare also reminds us that each major incident informs building more resilient systems, noting that they have always responded to failures by adding redundancy and automation.
Key Takeaway for SRE/DevOps Community
For the SRE/DevOps community, the key takeaway is a reconfirmation of “design for failure.” Even mature CDNs can be tripped by a subtle data bug if unchecked configuration changes ripple through the network. This incident – following closely on the heels of AWS’s outage – highlights how high-velocity engineering (“vibe coding” with AI tools) can create hidden failure surfaces. The rapid iteration culture demands equally rapid observability and testing countermeasures.
In practice, teams are now investing more in AI-powered testing pipelines (even for mobile and edge apps) and richer runtime diagnostics to catch complex bugs early.
Automation and Testing Frameworks Importance
For example, automated end-to-end testing and chaos testing can exercise new configuration flows before they hit prod. Similarly, enhanced tracing can pinpoint failures in ML-driven modules. Ultimately, as Cloudflare’s outage experience shows, strong automation and testing frameworks are essential to support the fast AI-driven workflows that define today’s engineering culture.