On Oct-19-2025, a serious outage struck Amazon Web Services’ DynamoDB in the US-EAST-1 (Northern Virginia) region. According to AWS, the AWS outage began at 11:48 PM PDT on October 19 and unfolded over roughly 15 hours.
During this time, the DynamoDB database in N. Virginia became unreachable, triggering cascading failures across many AWS services and causing global internet disruption. Major applications and platforms worldwide reported downtime or degraded performance. This post provides a technical timeline and analysis of the outage, what happened, why it happened, and how AWS responded.
Timeline of the AWS Outage
The outage progressed in distinct phases. AWS’s official postmortem and independent analyses detail the sequence of events:
How the AWS outage unfolded

- Oct 19, 11:48 PM PDT (Oct 20, 6:48 AM UTC) – DynamoDB DNS failure begins. Customers in us-east-1 and internal AWS systems started seeing increased DynamoDB API error rates. The root trigger was that the DynamoDB service’s regional endpoint (dynamodb.us-east-1.amazonaws.com) could no longer be resolved via DNS. All requests that needed DynamoDB began failing immediately.
- Oct 20, ~12:38 AM PDT – Root cause identified. AWS engineers traced the problem to DynamoDB’s DNS records by about 12:38 AM. They realized the public endpoint had been assigned an empty or invalid DNS record.
- Oct 20, 1:15 AM PDT – Mitigation applied. By ~1:15 AM, AWS applied temporary fixes that restored some internal access to DynamoDB and key tooling, easing the investigation. This involved manually pushing correct DNS entries so that internal AWS services could again reach DynamoDB.
- Oct 20, 2:25 AM PDT – DNS fully restored. At 2:25 AM, AWS engineers re-established the correct DNS records for the DynamoDB endpoint. Over the next ~15 minutes, as customers’ DNS caches expired, external applications regained the ability to resolve and connect to DynamoDB. By 2:40 AM, most clients could successfully connect again, marking primary recovery of the database service.
- Oct 20, 2:25 AM onward – Cascading EC2 failures. Even after DynamoDB was reachable, related services remained impaired. The EC2 instance launch system had partially broken down (see below). From this point until late morning, new EC2 instances in us-east-1 failed with “insufficient capacity” or limit errors.
- Oct 20, 5:28 AM PDT – EC2 control-plane recovery. By 5:28 AM, AWS completed manual resets and throttling of the EC2 Droplet Workflow Manager (DWFM), which allowed instance launches to start succeeding again. However, a backlog of pending tasks and networking updates remained.
- Oct 20, 5:30 AM – 2:09 PM PDT – NLB and network issues. Between ~5:30 AM and ~2:09 PM, customers saw increased errors on Network Load Balancers (NLBs) in us-east-1. This was due to a flood of delayed network state updates for newly launched instances, causing health-check failures. AWS introduced temporary fixes (like disabling automatic failovers) to stabilize NLBs.
- Oct 20, 1:50 PM PDT – Service fully restored. By early Monday afternoon, EC2 and most other services reported normal operation. AWS noted that by 1:50 PM PDT, all EC2 APIs and instance launches were back to normal. Other dependent services finished processing backlogs over the next day.
In summary, the initial DynamoDB DNS problem lasted only a few hours, but its side-effects on EC2, networking, and higher-level services prolonged the full recovery into the next day.
Root Cause of AWS outage: DNS Race Condition in DynamoDB
AWS confirmed that the outage originated in DynamoDB’s DNS management system. DynamoDB scales by dynamically managing hundreds of thousands of DNS records (via Amazon Route 53) for its load balancers. Automation must frequently update these records to add capacity or remove failed nodes. Crucially, AWS uses two distributed components: a DNS Planner that generates updated DNS “plans” for each endpoint, and multiple DNS Enactors in different Availability Zones that apply those plans via atomic Route 53 transactions.
Official AWS Postmortem
According to the official AWS postmortem, the AWS DNS outage in 2025 was caused by a latent race condition between two DNS Enactor processes. One Enactor became unusually slow because it had to retry multiple transactions and continued using an outdated DNS plan for a regional endpoint. At the same time, the Planner created new DNS plans that a second, faster Enactor quickly applied across all AWS endpoints. After finishing its updates, the fast Enactor initiated a cleanup routine that deleted older DNS plans across the system.
Unfortunately, the timing caused a major failure. Just as the slow Enactor finally applied its outdated plan to the DynamoDB endpoint, it was immediately removed by the cleanup process for being several generations behind. This deletion removed all IP addresses for dynamodb.us-east-1.amazonaws.com, leaving the DNS entry completely empty. As a result, the automated system stopped accepting new updates, forcing AWS engineers to perform manual intervention to rebuild and restore the correct DNS record.
What does this mean?
In practical terms, this meant that when the outage began, no client could resolve the DynamoDB hostname. Every DynamoDB API call in us-east-1 immediately failed with resolution errors. In short, a software bug in AWS’s internal DNS automation left the service invisible on the network.
Cascade: How the Failure Spun Out Across AWS
With DynamoDB unreachable, dependent systems began to break down in turn. The chain of failures unfolded as follows:
- EC2 Droplet Workflow Manager (DWFM): EC2 uses a subsystem called DWFM to track leases on physical servers (“droplets”) that host virtual machines. DWFM regularly checks in with DynamoDB to maintain the state of each droplet. When DynamoDB went offline, those state checks started timing out. Although running EC2 instances remained up, any droplet that needed to renew its lease or change state couldn’t do so. Over a couple of hours, thousands of droplet leases expired. Once DynamoDB was restored, DWFM attempted to re-establish all leases across the fleet. Because the accumulated backlog was huge, the system entered a “congestive collapse” and was unable to make forward progress. Engineers eventually had to throttle incoming work and restart many DWFM hosts around 5:28 AM. This cleared the queues and allowed leases to be re-established. Only then did new EC2 instance launches start to succeed again.
- Network Configuration Propagation: Separately, AWS’s Network Manager subsystem had built up a backlog of pending network configuration changes (to ensure new instances can communicate on the VPC network). After the DynamoDB fix, Network Manager began propagating all the delayed updates to newly launched EC2 instances and virtual networking appliances. Because so many instances had been launched out-of-order, this propagation took time. Until it caught up, many new instances lacked full connectivity.
- Network Load Balancers (NLBs): The delayed network configuration in turn caused NLBs to misinterpret instance health. NLBs constantly perform health checks on their backend targets (typically EC2 instances) and automatically remove any instance that fails health checks. In this event, new EC2 instances that had just started up were not fully network-enabled, so some health checks were failing. The NLB health-check system temporarily pulled these instances out of service, then put them back when the checks eventually passed. As a result, between about 5:30 AM and early afternoon, customers saw a surge in “connection errors” on their NLBs in us-east-1. AWS disabled automatic health-check failovers and limited the rate of NLB capacity removal to stabilize the situation.
- Other AWS Services: The EC2 and networking disruptions affected many higher-level services. For example, container and orchestration platforms (ECS/EKS), AWS Lambda, and serverless operations all rely on EC2 resources and DynamoDB in the background, so they experienced failures or throttle limits. Amazon Redshift (data warehousing) and AWS Security Token Service (STS) faced delays too, because they had to retry workflows when underlying EC2 instance launches initially failed. In practice, many AWS teams spent Monday night working through backlogs of failed operations: for some services, the final cleanup extended into the next day.
In summary, a single DNS failure in DynamoDB caused a domino effect: it broke EC2’s orchestration, which in turn broke networking and higher-level services. AWS had to recover in phases, first fixing the DNS, then clearing the dependent system backlogs, then processing queued work, and finally allowing customer applications to fully recover.
Global Impact of AWS outage on Applications
The outage in us-east-1 had widespread customer impact. DynamoDB powers many AWS-hosted applications, so its outage disrupted thousands of websites and apps. During the incident, over four million users reported errors, and the downtime impacted at least a thousand companies across various industries.
Regions
In the US and abroad, the outage knocked workers from London to Tokyo offline. Users complained of failures in everyday services – for example, digital payment app Venmo and video-call service Zoom both had outages or errors reported by Monday afternoon.
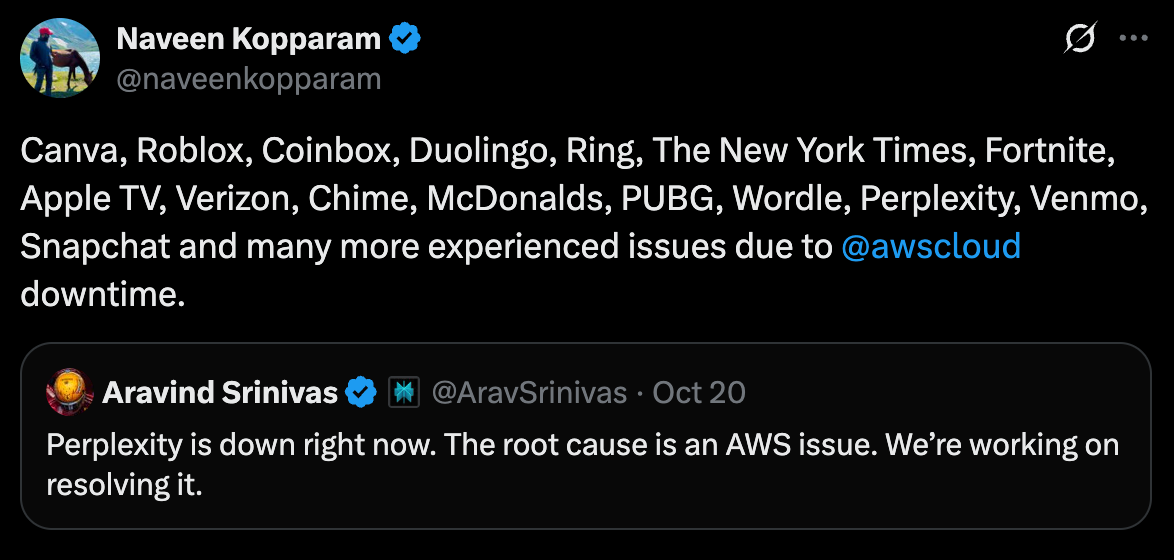
Sectors
High-profile consumer services spanning social media, gaming, finance, and enterprise all reported disruptions. Apps like Reddit, Snapchat, Roblox, and Duolingo had all been affected. Gaming and crypto were hit too – Fortnite, Clash Royale/Clans, Perplexity AI, Coinbase, and Robinhood all cited AWS outages.
Amazon’s own services
Even Amazon’s own properties – its retail website, Prime Video streaming, and Alexa voice service – saw interruptions. In effect, platforms “from Snapchat to Venmo” went dark for some users during the outage. Analysts noted that for major businesses, hours of cloud downtime translate to millions in lost productivity and revenue, highlighting the economic scale of the disruption.
AWS acknowledged the broad effects. This was the third major AWS US-EAST-1 outage in five years, reflecting how a problem in this central region can trigger a global knock-on effect. The outage underscored the interdependence of modern online services on a few cloud providers. Experts noted that it highlights the dependency we have on relatively fragile infrastructures.
AWS Response and Mitigation
AWS released an official post-incident report describing the cause and its remediation steps. In brief, AWS has disabled the faulty DNS automation and is deploying multiple safeguards. The DynamoDB DNS Planner and Enactor processes have been turned off worldwide until the bug is fixed. AWS plans to correct the race condition in the system and add protections to block any “incorrect DNS plans” from being applied.
In addition, AWS will strengthen testing and throttles in related systems: for EC2, it is adding tests of the DWFM recovery path and improving throttling of instance-launch requests; for NLB, it will limit how rapidly an individual balancer can shed capacity when health checks fail. These measures aim to prevent a similar bug from bringing down a critical endpoint again and to better contain cascading failures if one occurs.
AWS also apologized to customers and said it is learning from this event to improve availability. The company emphasized its track record of high availability but acknowledged the severity of this outage. The immediate fixes included temporarily disabling the DynamoDB DNS Planner, adding additional protections to prevent incorrect DNS entries, and improving testing metrics to catch such errors before they can cause extended outages.
Conclusion
The AWS DynamoDB outage in October 2025 showed how a small software bug can trigger massive cloud disruption. A hidden race condition in AWS’s DNS automation deleted all addresses for the DynamoDB endpoint, instantly cutting off apps that depended on the database. The failure spread quickly through AWS infrastructure, halting EC2 provisioning, disrupting load balancers, and freezing higher-level services. Engineers had to manually rebuild DNS records and throttle requests before restoring normal operations.
This AWS outage revealed how fragile large-scale cloud systems can be when core dependencies fail. AWS’s postmortem detailed the root cause and outlined fixes to prevent future incidents. While services recovered by Monday afternoon, many organizations spent hours clearing backlogs of failed requests. The AWS outage reminded businesses worldwide that even mature cloud platforms can experience cascading failures — and why ongoing resilience testing is essential in modern cloud operations.