Artificial intelligence is transforming software development. Tools like GitHub Copilot act as an AI coder to assist developers by generating code snippets, while dedicated AI code review tools such as CodeRabbit and Greptile analyze pull requests (PRs) and suggest improvements.
These AI tools aim to improve pull request reviews and embed into best practices for enterprise CI/CD pipelines, catching bugs early and speeding up releases. Below we compare CodeRabbit and Greptile on key metrics like bug detection and comment quality, using recent benchmark data and analysis.
Player 1: CodeRabbit
CodeRabbit is optimized for PR-centric analysis with an emphasis on fast execution, concise summaries, and developer-readable feedback. It focuses on identifying logic issues, validation gaps, and maintainability concerns directly within the scope of a pull request, while minimizing comment volume.
Features:
- PR-scoped analysis optimized for fast feedback in CI/CD pipelines
- Emphasis on concise summaries and conversational, developer-readable comments
- Strong at identifying logic errors, validation gaps, and maintainability issues within diffs
- Designed to minimize review noise and false positives
- Low setup and tuning overhead; quick to integrate into existing workflows
- Best suited for high-velocity teams and PR-heavy repositories
Player 2: Greptile
Greptile, in contrast, performs broader codebase-aware analysis, leveraging deeper context to detect critical bugs, security issues, and architectural inconsistencies. Its approach favors coverage and correctness over brevity, often producing richer and more numerous findings.
Features:
- Full codebase–aware analysis with deep contextual reasoning
- Strong focus on critical bug detection, security issues, and architectural risks
- Broader coverage across maintainability, correctness, and system design concerns
- Higher comment volume due to exhaustive scanning and richer feedback
- Typically requires more tuning and reviewer bandwidth
- Best suited for large, complex, or security-sensitive codebases
Both tools exemplify the shift toward AI-augmented code review as a CI/CD primitive, enabling earlier defect detection and reducing reliance on purely manual inspection. The following sections compare CodeRabbit and Greptile using benchmark data and qualitative analysis to evaluate their effectiveness, trade-offs, and suitability for different engineering workflows.
Evaluation Setup and Categories
In a recent independent evaluation, real open-source PRs were reviewed by both CodeRabbit and Greptile under the same conditions. Comments from each tool were categorized into types engineers care about:
- Critical Bugs: Severe defects (e.g. a SQL injection) that break functionality or security.
- Refactoring: Suggestions to improve code structure or remove duplication.
- Performance Optimization: Ideas to make code faster or use less memory.
- Validation: Checking logic and edge cases (e.g. verifying API error handling).
- Nitpicks: Minor style/format fixes.
- False Positives: Incorrect flags where the code is actually fine.
These categories help assess not just how many issues each tool catches, but the signal-to-noise ratio of their feedback (engineers prefer high-value comments over trivial nits).
Comparative Results
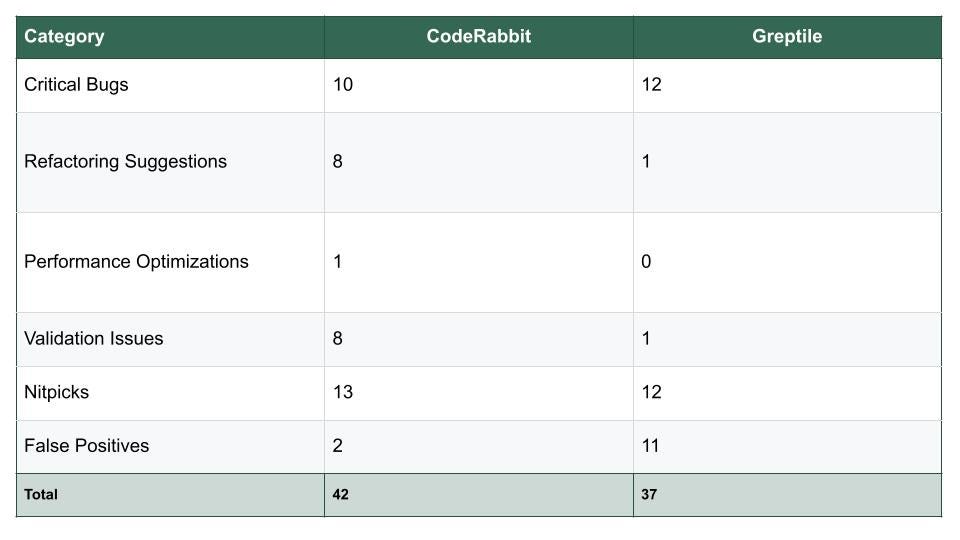
Key Observations
1. Critical Bug Detection
Greptile slightly edged out CodeRabbit in catching critical bugs (12 vs. 10). While both detected major issues that could cause runtime failures or severe security risks, Greptile’s marginal lead suggests a stronger focus on high-severity vulnerabilities.
2. Code Improvement Suggestions
CodeRabbit clearly outperformed Greptile in refactoring recommendations (8 vs. 1) and validation issues (8 vs. 1). This shows CodeRabbit is more proactive about long-term maintainability and ensuring code changes meet intended requirements.
3. Performance Optimization
Only CodeRabbit flagged performance-related issues (1 vs. 0). While the number is small, these optimizations can be impactful in high-scale environments.
4. Noise and False Positives
False positives — feedback that’s incorrect or irrelevant — can slow down teams. Greptile had a much higher count here (11 vs. 2 for CodeRabbit), suggesting CodeRabbit produces cleaner, more actionable reviews.
These findings can be summarized as:
- Bug Catch: Greptile 76% vs. CodeRabbit 82%
- Comments/Noise: Greptile High vs. CodeRabbit Moderate
- Feedback Quality: Both high (good clarity and actionable comments)
- PR Summary: Both Excellent
- Avg. Wait Time: Greptile ~288s, CodeRabbit ~206s
These metrics help explain how each tool would fit into a development workflow. Greptile’s strength is in maximum bug detection — it flags the most issues (critical bugs, security flaws, etc.). CodeRabbit, on the other hand, provides slightly faster, more streamlined reviews with fewer low-value comments.
Improving PR Reviews & CI/CD
AI-assisted reviews like CodeRabbit or Greptile embody best practices for modern CI/CD. By integrating an AI code review tool into the pipeline, teams can improve pull request reviews by catching errors automatically before code is merged. This follows enterprise CI/CD best practices: automated analysis and PR checks help maintain code quality at scale. Research shows manual reviews alone often slow teams down and miss issues that machines can catch quickly. Automating PR reviews with smart tools accelerates development: reviewers focus on high-level design, while the AI handles routine checks.
For teams looking to buy an AI code review tool, these benchmarks offer guidance. Key factors include bug coverage (how many real bugs are caught) and signal-to-noise ratio (how many suggestions are actually useful). For example, one test found Greptile caught nearly every critical bug, whereas CodeRabbit missed more but produced fewer extraneous alerts. In practice, teams prioritizing strict bug-detection (e.g. security) may lean toward Greptile, while teams valuing brevity and speed might favor CodeRabbit.
In either case, using an AI reviewer helps follow best practices: every PR is automatically checked, nothing slips through, and developers spend time reviewing or merging rather than hunting for typos or minor issues.
CodeRabbit vs. Greptile — High-Level Comparison
| Dimension | CodeRabbit | Greptile |
|---|---|---|
| Primary goal | Improve PR clarity, speed, and collaboration | Maximize bug detection and deep codebase analysis |
| Review philosophy | Concise, conversational, developer-friendly | Thorough, analytical, and exhaustive |
| Critical bug detection | Strong, but not maximal | Very strong, prioritizes high-severity issues |
| Refactoring guidance | Proactive and frequent | Limited, more selective |
| Performance suggestions | Occasionally provided | Rare |
| Validation & edge cases | Frequently flagged | Less emphasis |
| Signal-to-noise ratio | Moderate-to-high signal, fewer false positives | Lower signal due to higher comment volume |
| False positive tendency | Relatively low | Higher, especially with broad scans |
| PR summaries | Clear, well-structured, easy to skim | Clear, comprehensive |
| Review latency | Faster turnaround | Slower due to deeper analysis |
| Setup & configuration | Simple onboarding, low tuning | More setup and tuning required |
| Best-fit codebase | Active PR-heavy repos, fast iteration | Large, complex, or security-critical codebases |
| Ideal team profile | Teams optimizing for speed and collaboration | Teams optimizing for maximum correctness and coverage |
| CI/CD fit | Lightweight, integrates smoothly into fast pipelines | Heavyweight, suited for rigorous quality gates |
How to Interpret This Table
- Choose CodeRabbit if your team values fast feedback, cleaner PRs, and lower review friction while still catching meaningful issues.
- Choose Greptile if your top priority is catching as many bugs and vulnerabilities as possible, even at the cost of more comments and slower reviews.
Why Panto AI Offers More Than Both CodeRabbit and Greptile
While CodeRabbit and Greptile excel in specific niches—fast, streamlined reviews and deep bug detection, respectively—Panto AI bridges the gap between speed, signal quality, and broader code insight. Where CodeRabbit focuses primarily on review clarity and Greptile emphasizes exhaustive scanning, Panto AI is designed to deliver context-aware feedback that scales with team complexity and codebase maturity.
Panto AI not only highlights critical issues but also helps teams understand intent, patterns, and long-term maintainability. Its feedback goes beyond isolated bug flags to include explanations that improve alignment, reduce ambiguity, and support shared coding standards. This ensures that developers aren’t just fixing surface-level problems but are also gaining insights that elevate overall code health.
Moreover, Panto AI’s approach minimizes noise while maximizing actionable, high-signal commentary across diverse tech stacks and workflows. Instead of forcing teams to choose between lean reviews and thorough analysis, Panto AI provides a balanced, adaptive experience—making it especially suitable for organizations that need consistent code quality, low cognitive load, and sustainable velocity in modern CI/CD pipelines.
CodeRabbit vs. Greptile vs. Panto AI
| Dimension | CodeRabbit | Greptile | Panto AI |
|---|---|---|---|
| Primary focus | Fast, conversational PR reviews | Deep, exhaustive bug and quality detection | Balanced, context-aware code quality |
| Review depth | Moderate | Very deep | Deep where it matters |
| Speed of feedback | Fast | Slower due to heavy analysis | Fast, with controlled depth |
| Signal-to-noise ratio | Moderate–high | Lower (more comments) | High (designed to avoid overload) |
| Critical bug detection | Strong | Very strong | Strong, with contextual prioritization |
| Refactoring guidance | Frequent, lightweight | Limited and selective | Actionable, maintainability-focused |
| Performance insights | Occasional | Rare | Context-driven when relevant |
| False positive risk | Lower | Higher | Low |
| Setup & tuning effort | Minimal | Higher | Low |
| Best-fit teams | Fast-moving, PR-heavy teams | Security- or correctness-first teams | Teams optimizing for sustainable velocity |
| Codebase fit | Greenfield or rapidly changing repos | Large, complex, legacy-heavy systems | Mixed-maturity, multi-language codebases |
| Overall positioning | Speed and collaboration | Maximum coverage and depth | Best balance of depth, clarity, and usability |
Conclusion and Recommendations
In summary, CodeRabbit, Greptile, and Panto AI are among the strongest AI code review tools for modern development. Greptile excelled at raw bug detection, while CodeRabbit generated fewer superfluous comments. Panto AI complements these approaches by emphasizing context-aware, high-signal feedback that balances correctness, maintainability, and reviewer bandwidth.
If you need maximum bug detection, Greptile performs best. Teams seeking leaner reviews and faster turnaround may prefer CodeRabbit. Teams operating between these extremes—who want meaningful quality improvements without exhaustive analysis or narrow scope—may find Panto AI the best fit.
Adopting an AI-driven code review agent is a proven way to improve pull request reviews and maintain high standards at scale. Teams planning to invest in such tooling should weigh these trade-offs carefully—using benchmark data and workflow fit to select the solution best aligned with their engineering priorities.