This blog is a comparison between Greptile and Panto AI code review capabilities. It walks the user through straight facts and statistics and no conclusion, so they can make their own. To be fully transparent, at the end of the doc, we have also open-sourced the framework, reviews, comments, and repos used for readers to go back and verify.
There are two known popular ways to compare any SAAS product in the market: based on features and based on quality. Tertiary values like pricing, sales approach, onboarding flow, and UI/UX do matter, but for the business we are in of code quality, security, and review, the cost of a single bad code being allowed into production is so high that each of the above metrics is overpowered by the quality of review and how we perform.
How We Conducted the Benchmark?
To conduct a fair comparison, we signed up with our competitors and reviewed a set of neutral pull requests (PRs) from the open-source community. Each PR was analyzed independently by both Panto AI and Greptile. We at Panto AI then used a large language model (LLM) to categorize the comments into different segments, reflecting how engineers perceive them in a real-world code review process.
To ensure fairness, we at Panto AI have left the categorization entirely to the LLMs.
Key Comment Categories in AI Code Review
We at Panto AI have classified all code review comments into the following categories, ranked by importance from highest to lowest:
Critical Bugs
A severe defect that causes failures, security vulnerabilities, or incorrect behavior, making the code unfit for production. These issues require immediate attention.
Example: A SQL injection vulnerability.
Refactoring
Suggested improvements to code structure, design, or modularity without changing external behavior. These changes enhance maintainability and reduce technical debt.
Example: Extracting duplicate code into a reusable function.
Performance Optimization
Identifying and addressing inefficiencies to improve execution speed, memory usage, or scalability.
Example: Use React.memo(Component) to prevent unnecessary re-renders.
Validation
Ensuring the correctness and completeness of the code concerning business logic, functional requirements, and edge cases.
Example: Checking if an API correctly handles invalid input or missing parameters.
Note: While valuable, repeated validation comments can become frustrating when they appear excessively.
Nitpick
Minor stylistic or formatting issues that don’t affect functionality but improve readability, maintainability, or consistency.
Example: Indentation, variable naming, and minor syntax preferences.
Note: Engineers often dislike these being pointed out.
False Positive
A review comment or automated alert that incorrectly flags an issue when the code is actually correct.
Example: A static analysis tool incorrectly marking a variable as unused.
Note: False positives waste engineers’ time and defeat the purpose of automated code reviews.
Benchmarking Methodology: How We Compared Greptile vs Panto AI
To ensure a fair comparison, we followed these principles:
- We compiled a list of all open-source PRs, 17 to be precise and reviewed each of them with both Panto AI and Greptile.
- We used OpenAI’s o3-mini API (best for coding) to classify comments, rather than relying on human judgment, as code reviews are inherently subjective and prone to bias.
- We eliminated words or tags like Important, Security, or Critical from bot-generated comments to prevent the LLM from being influenced by predefined labels.
By open-sourcing this benchmark, we at Panto AI aim to provide complete transparency and help developers choose the best AI-powered code review tool for their needs.
Results
| pantomaxbot[bot] | greptile-apps[bot] | |
| CRITICAL_BUG | 12 | 12 |
| REFACTORING | 14 | 1 |
| PERFORMANCE_OPTIMIZATION | 5 | 0 |
| VALIDATION | 0 | 1 |
| NITPICK | 3 | 12 |
| FALSE_POSITIVE | 4 | 11 |
| OTHER | 0 | 0 |
| SUM | 38 | 37 |
What we liked about Greptile is they are also a no nonsense code reviewer like us. They don’t do poems, unnecessary UI enhancements and modules on extended version control systems like coderabbit which makes lives of developers difficult by adding more clicks. They are to the point which can be ideal from a UX perspective.
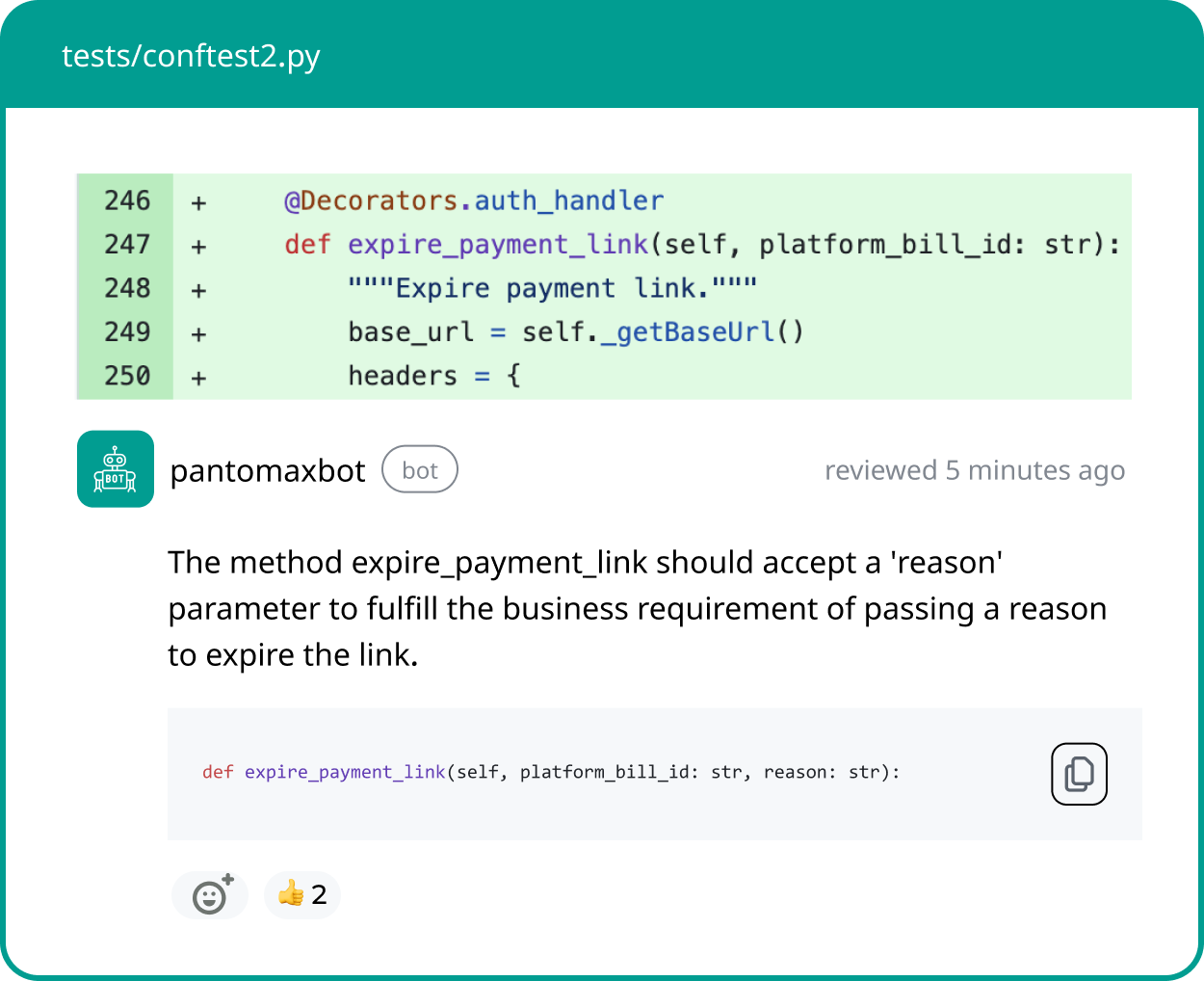
In terms of flagging critical bugs, they flagged exactly the same suggestions as Panto AI. There were a few that caught our attention.
If a change includes both refactoring and performance optimization, it’s even more important to flag it. Refactoring implies no behavioral change, while performance optimization often alters runtime characteristics. Flagging ensures reviewers assess the safety of structural changes and validate the intended performance impact without missing either.
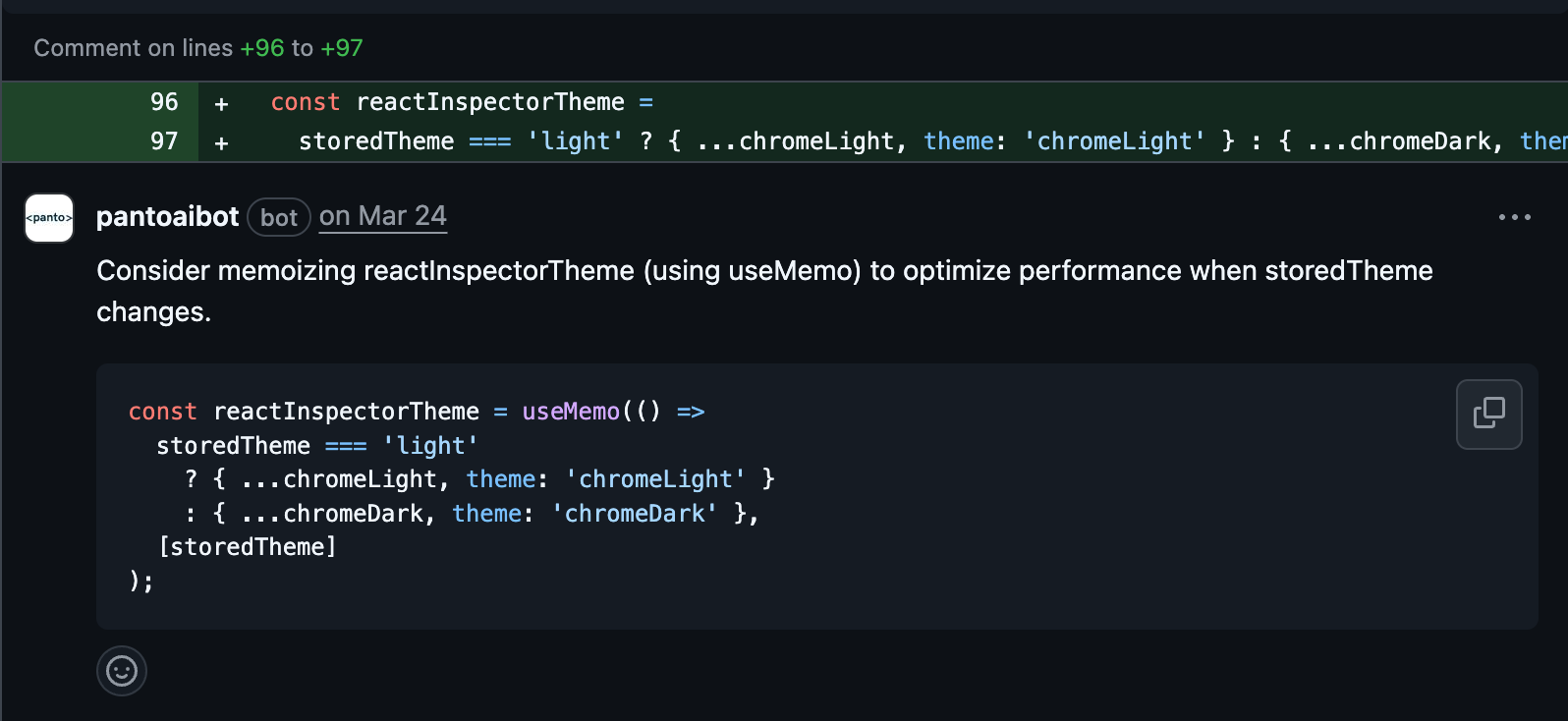
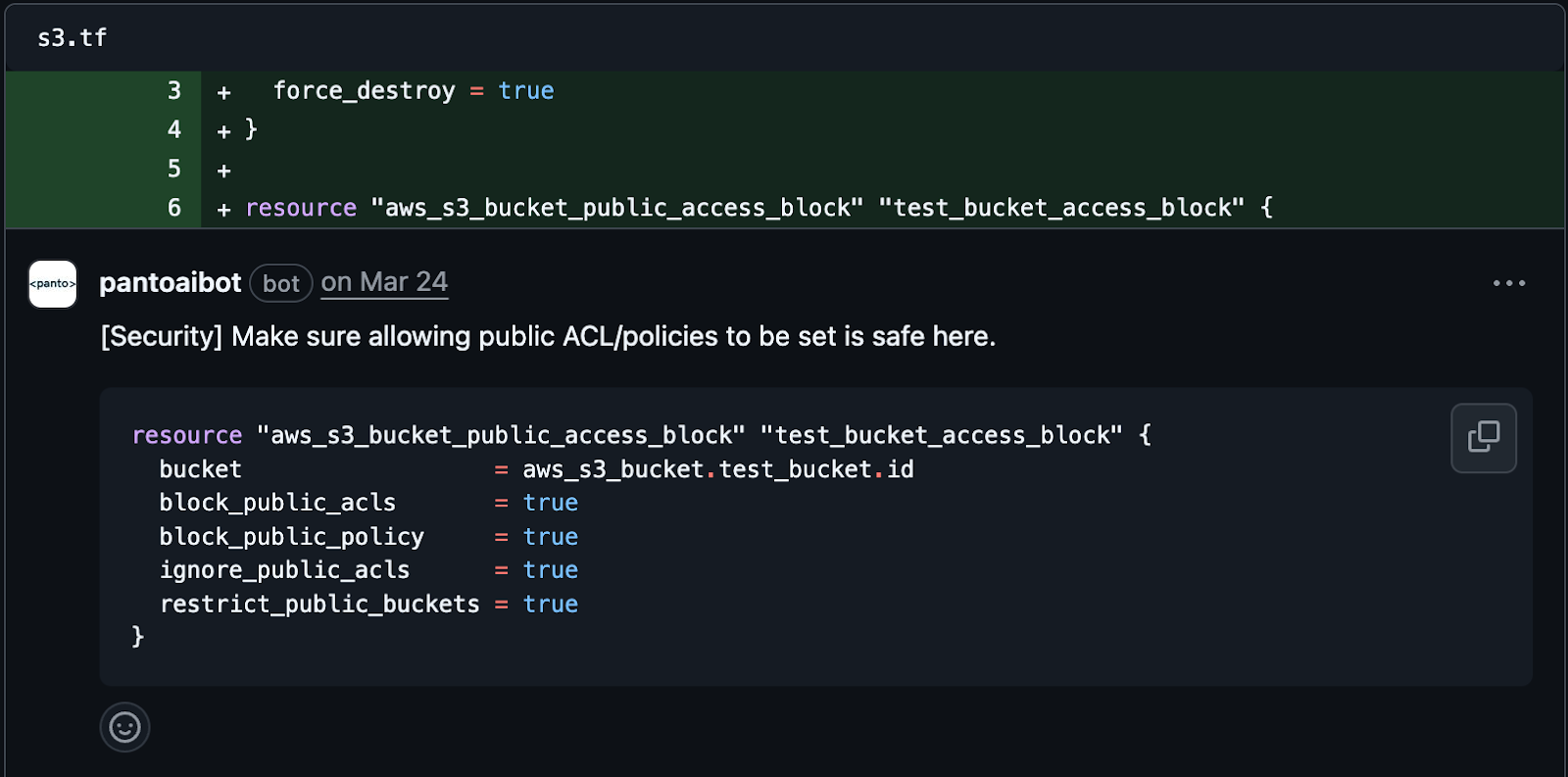
We observed Greptile to be pathetic at this. Panto pays a lot of attention to help developers to do code reviews without being distracted by what is absolutely important and what is actual hygiene. They might have different priorities but both are important. We flagged 14x more comments than greptile in this category.
These are few of interesting Refactoring and Performance optimisation suggestions Panto made:
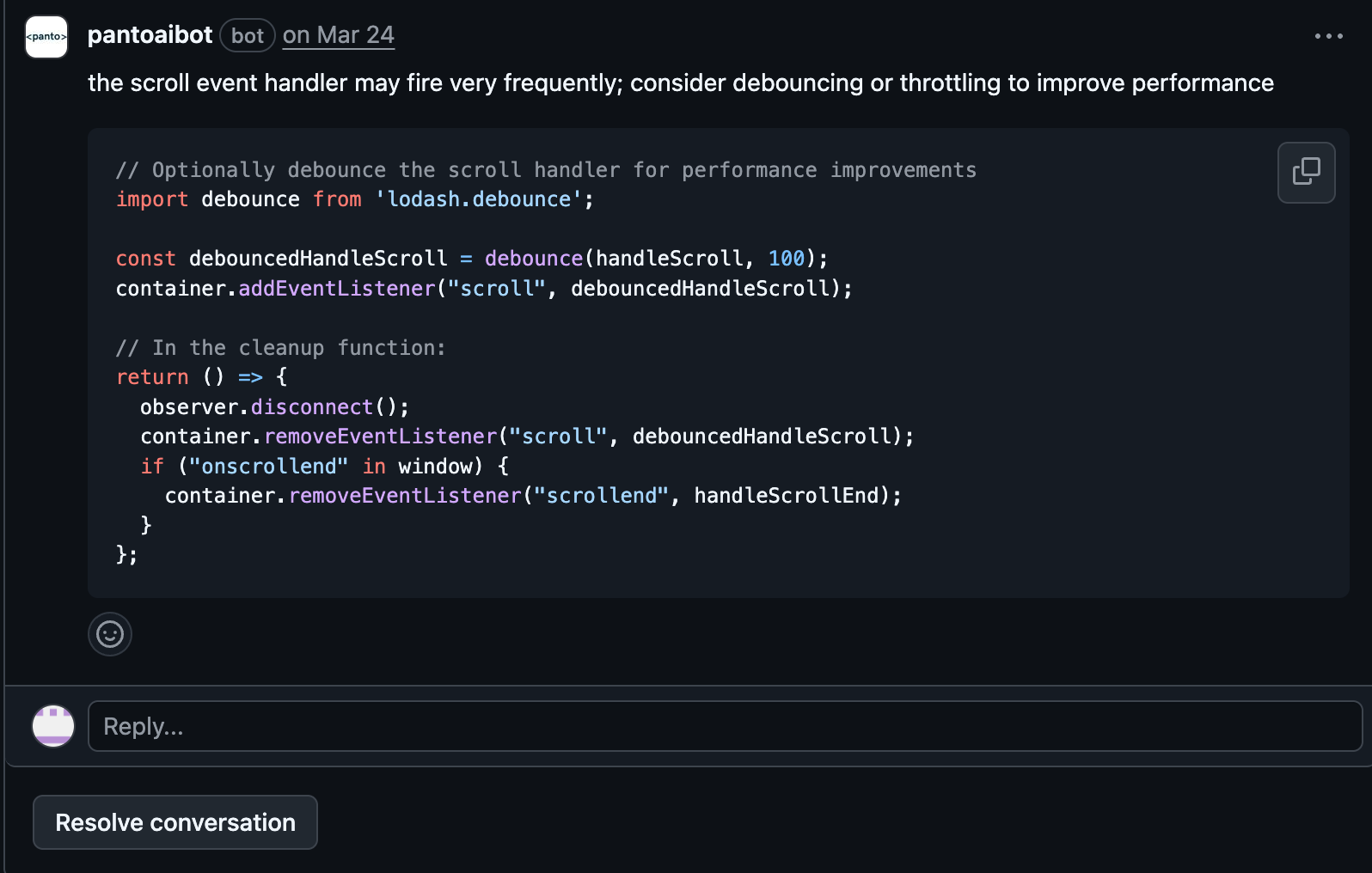
What was the most disappointing part about Greptile for us was the signal to noise ratio. We at panto have always boasted of this. In case of code reviews, which are very subjective, if there is one extra comment or review, the affinity of developers to read comments or seek review drastically reduces. It is highly recommended to have a high signal to noise ratio and we saw a huge gap.
Conclusion
Well, it’s hard to be 100% accurate in solving problems which are subjective. We do have noise in Panto AI as well but the order and magnitude talks for itself. Close to 60% of all reviews made by Greptile fell into either nitpick or a false positive category.
Here below is open source framework, the data fetched, repos used, comments made by Greptile and Panto AI both. If you are an engineering manager considering a code review agent, You can either make a data backed decision from above or make an analysis of your own using our framework for your set of PRs.