On June 12, 2025, Google Cloud Platform (GCP) suffered a major outage that rippled across the internet. Popular services like Spotify, Discord, Snapchat and others reported widespread failures, as did Google’s own Workspace apps (Gmail, Meet, Drive, etc.). Downdetector showed ~46,000 outage reports for Spotify and ~11,000 for Discord at the peak. According to Google’s status dashboard, the incident began at 10:51 PDT and lasted over seven hours (ending around 6:18 p.m. PDT). In other words, a single configuration error in Google’s control plane caused a global disruption of cloud APIs, authentication, and dependent services.
Underlying Cause: Service Control Crash
Google’s official incident report pins the outage on a null pointer exception in its Service Control system — the gatekeeper for all Google Cloud API calls. Service Control handles authentication, authorization (IAM policy checks), quota enforcement, and logging for every GCP request. On May 29, 2025, Google deployed a new feature in Service Control to support more advanced quota policies. This code lacked proper error handling and was not feature-flagged, meaning it was active everywhere even though it depended on new kinds of policy data.
Two weeks later (June 12), an unrelated policy update inadvertently inserted a blank/null value into a Spanner database field that Service Control uses. Within seconds this malformed policy replicated globally (Spanner is designed to sync updates in real time across regions). As each regional Service Control instance processed the bad policy, it followed the new code path and hit an unexpected null. The result was a null pointer exception crash loop in every region. In Google’s own words: “This policy data contained unintended blank fields… [which] hit the null pointer causing the binaries to go into a crash loop”. In short, a central database field was nullable, a new policy change wrote a blank value into it, and the Service Control code didn’t check for a null pointer exception — so every instance simply crashed.
This kind of failure has been dubbed the “curse of NULL”. As one commentator noted, “allowing null pointer exceptions to crash critical infrastructure services is a fundamental failure of defensive programming”. In normal circumstances a missing value would be caught by a null check or validation, but here the code path was untested (no real policy of that type existed in staging) and unprotected. The combination of a missing feature flag, no null-check, and instant global replication turned one tiny blank entry into a worldwide outage.
Timeline of the Outage
The failure happened extremely fast, but Google’s SRE teams also moved quickly once it started. Within 2 minutes of the first crashes (just after 10:51 a.m. PDT), Google’s Site Reliability Engineering (SRE) team was already triaging the issue. By 10 minutes in, they had identified the bug (the new quota feature) and activated the built-in “red button” kill-switch for that code path. The red-button (a circuit-breaker to disable the faulty feature) was globally rolled out within ~40 minutes of the incident start. Smaller regions began recovering shortly after, but one large region (us-central in Iowa) took much longer — about 2 hours 40 minutes — to fully stabilize.
Several factors slowed recovery. First, as Service Control instances all restarted en masse, they simultaneously hammered the same Spanner database shard (“herd effect”), overwhelming it with requests. Because the retry logic lacked randomized backoff, this created a new performance bottleneck. Engineers had to manually throttle and reroute load to get us-central1 healthy. Second, Google’s own status and monitoring systems were down (they ran on the same platform), so the first public update on the outage appeared almost one hour late. (Customers saw status dashboards either blank or reporting “all clear” despite the crisis.) Meanwhile, thousands of customers were seeing 503/401 errors — some saw timeouts, some saw permission denials — depending on how far requests got in the authorization chain.
Engineering Oversights
A series of basic engineering lapses turned a code bug into a global outage:
- No Feature Flag or Safe Rollout: The new quota-checking code was deployed globally in active mode, without a gradual rollout or toggle to disable it safely. Had it been behind a flag, Google could have limited its scope or killed it before it hit customers.
- Missing Null Pointer Exception (Defensive Coding): The faulty code never checked for null or blank inputs. When the blank policy field appeared, it immediately threw a
NullPointerException, crashing the service in every region. In modern engineering, hitting a null should never be allowed to crash a core service. - Global Replication Without Staging: Policy changes in Spanner are propagated worldwide in seconds. There was no quarantine or validation step for configuration data. A single malformed update instantly poisoned every region.
- No Exponential Backoff: During recovery, all Service Control instances retried simultaneously. Because there was no randomized throttling, they flooded the database (the “thundering herd”), delaying convergence.
- Monolithic Control Plane: Service Control is a central choke-point for all API requests. Its failure meant most Google Cloud services lost the ability to authorize requests at all. Ideally, critical checks should be compartmentalized or have fail-open defaults.
- Communication Blindspot: Google’s incident dashboard and many tools were on the affected platform. The first public acknowledgement came ~60 minutes late, leaving customers confused. In a serious outage, “the status page going down” is as bad as the outage itself.
Each of these points is a classic reliability precaution — yet all were missed simultaneously. As one analyst put it, Google had “written the book on Site Reliability Engineering” but still deployed code that could not handle null inputs. In hindsight, this outage looks like a string of simple errors aligning by unfortunate chance.
Best Practices and Code Example
This incident highlights why defensive coding and strong validation matter, even (especially) at the infrastructure level. For example, a simple null-check in a code snippet could have prevented the crash:
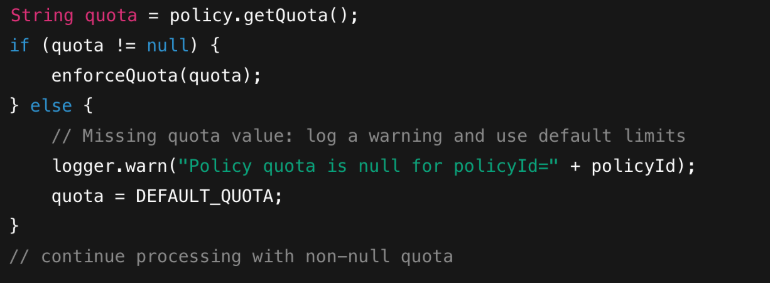
Key takeaways for reliability engineers and architects:
- Use Feature Flags for All Changes: Always wrap new behavior in a toggle so it can be disabled instantly if something goes wrong. Staged rollouts (e.g. per-region or per-customer) help catch bugs before they reach global scale.
- Validate Config and Schemas: Enforce strict schemas or non-null constraints on critical data. Reject or sanitize any configuration change that has missing or unexpected values. (Here, making the Spanner field NOT NULL or validating updates in a testbed could have caught the error.)
- Defensive Programming: Never trust input blindly. Check for nulls or out-of-range values even in production code. Fail open if possible — for example, if a policy check fails, allow default behavior rather than dropping all traffic.
- Limit Blast Radius: Design services to degrade gracefully. Use circuit breakers so that if one component fails, it doesn’t cascade. For instance, Service Control could have defaulted to “allow” when policy info was unavailable, so clients could still function in read-only or default mode.
- Backoff and Jitter on Restarts: When restarting thousands of tasks, add randomized exponential backoff so they don’t all hit the same backend at once. This prevents a “herd effect” that can make recovery even slower.
- Separate Monitoring Infrastructure: Ensure that your status page, alerts, and logs do not live on the same failing system. An independent health-check mechanism (or multi-cloud observability) can provide visibility when your main stack is down.
In this case, Google has since pledged to adopt many of these practices (modularizing Service Control, enforcing flags, improving static analysis and backoff, etc). But these should have been in place before the outage. The lesson is that even a “one-off” null reference can bring down a giant — so engineers must assume the worst, validate rigorously, and build in multiple layers of protection.
Where AI Code Review Fits In: Catching the Subtle but Critical
One of the most telling aspects of the June 12 outage is that nothing exotic went wrong. There was no zero-day exploit, no database meltdown, no AI hallucination-just an unguarded null. The kind of thing that’s easy to overlook in a manual review, especially in unfamiliar or dormant code paths.
Modern engineering teams are increasingly supplementing their manual code review process with AI-assisted reviewers that help catch these low-signal, high-impact bugs earlier. This includes:
- Unguarded access of potentially null fields
- Assumptions in deserialization or config-parsing
- Branch logic that lacks feature flag guards
- Unvalidated external inputs injected into infrastructure systems
At Panto, we’ve seen this pattern recur frequently: a missing guard clause in a backend service, a policy loader that assumes presence, or a rollout script that assumes data consistency.
Below are a few real examples where Panto flagged null-pointer-risky patterns early:
“Always verify new fields are fully integrated into the codebase and handled gracefully in all scenarios. Early feedback can prevent issues before they escalate.”
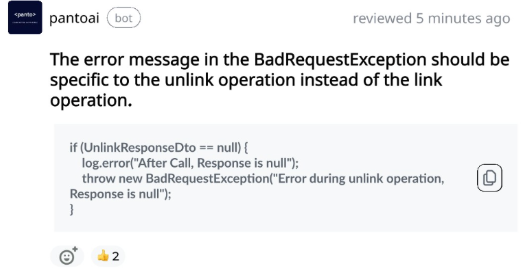
“Using a specific error message in the BadRequestException that accurately reflects the unlink operation is essential for maintaining clarity and correctness in the codebase. When an unlink action fails but the error refers to linking instead, it creates confusion for developers and users alike.”
Closing Thoughts
Tools like Panto don’t replace experienced reviewers but they provide another critical layer of defense against silent-but-deadly bugs. When a single unguarded null can bring down even the most resilient cloud platforms in the world, there’s little excuse to leave such gaps unchecked.
Build software systems that are resilient by design and backed by a review culture that assumes nothing and checks everything. Try Panto today for an easy, effective trial—and experience the difference.