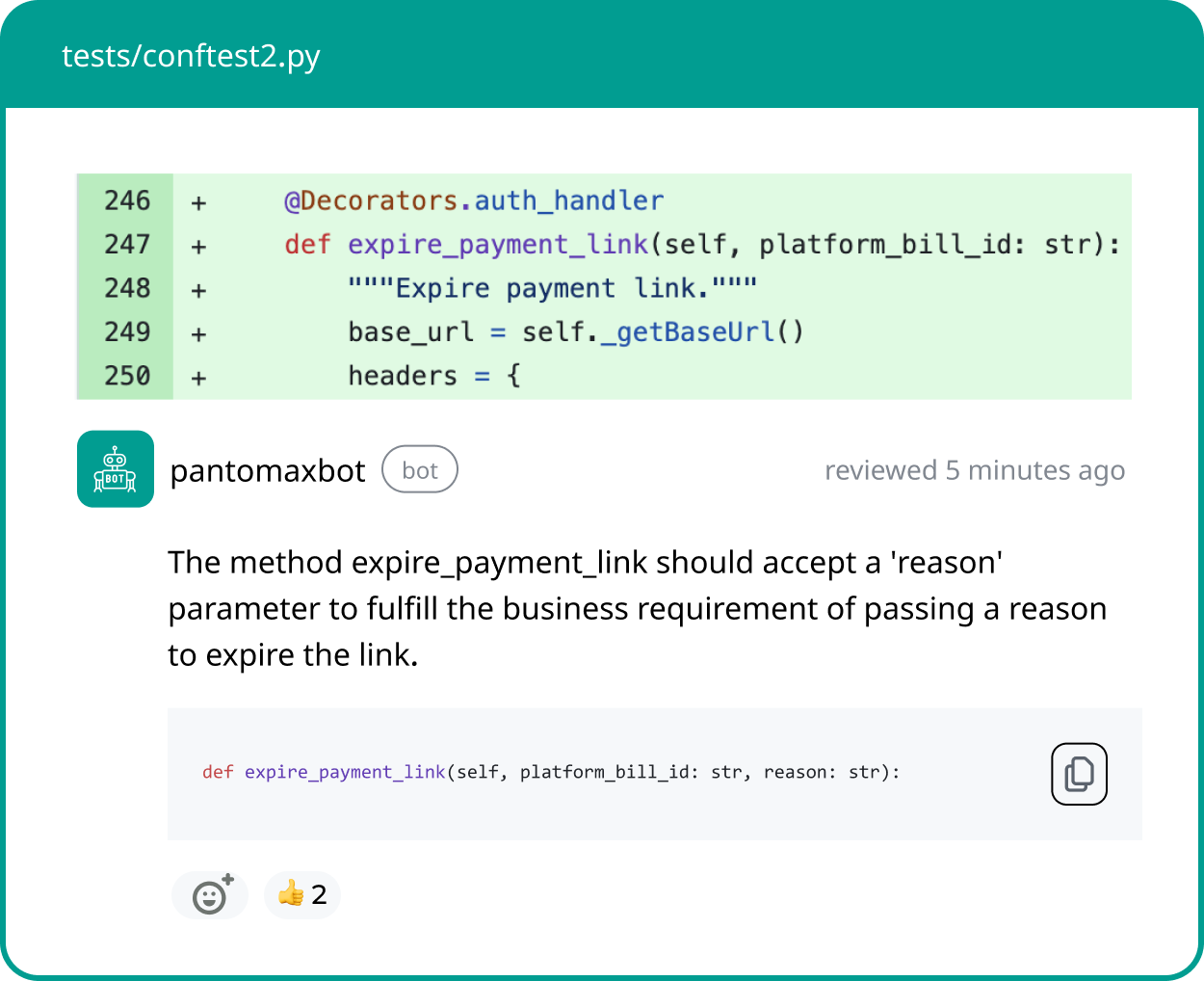
Most tools claim to automate code reviews, but very few actually deliver where it matters: depth, accuracy, and real developer trust. In this post, we put CodeAnt and Panto AI to the test, not with marketing checklists but with real-world code and actual pull requests.
This is not a pitch. It is a head-to-head comparison rooted in one question: when something critical is about to go to production, which tool would you trust to catch it? We have open-sourced every repo, comment, and output so you can see the truth for yourself.
How We Conducted the Benchmark?
To conduct a fair comparison, we signed up with our competitors and reviewed a set of neutral pull requests (PRs) from the open-source community. Each PR was analyzed independently by both Panto AI and Codeant AI. We at Panto AI then used a large language model (LLM) to categorize the comments into different segments, reflecting how engineers perceive them in a real-world code review process.
To ensure fairness, we at Panto AI have left the categorization entirely to the LLMs.
Key Comment Categories in AI Code Review
We at Panto AI have classified all code review comments into the following categories, ranked by importance from highest to lowest:
Critical Bugs
A severe defect that causes failures, security vulnerabilities, or incorrect behavior, making the code unfit for production. These issues require immediate attention.
Example: A SQL injection vulnerability.
Refactoring
Suggested improvements to code structure, design, or modularity without changing external behavior. These changes enhance maintainability and reduce technical debt.
Example: Extracting duplicate code into a reusable function.
Performance Optimization
Identifying and addressing inefficiencies to improve execution speed, memory usage, or scalability.
Example: Use React.memo(Component) to prevent unnecessary re-renders.
Validation
Ensuring the correctness and completeness of the code concerning business logic, functional requirements, and edge cases.
Example: Checking if an API correctly handles invalid input or missing parameters.
Note: While valuable, repeated validation comments can become frustrating when they appear excessively.
Nitpick
Minor stylistic or formatting issues that don’t affect functionality but improve readability, maintainability, or consistency.
Example: Indentation, variable naming, and minor syntax preferences.
Note: Engineers often dislike these being pointed out.
False Positive
A review comment or automated alert that incorrectly flags an issue when the code is actually correct.
Example: A static analysis tool incorrectly marking a variable as unused.
Note: False positives waste engineers’ time and defeat the purpose of automated code reviews.
Benchmarking Methodology
To ensure a fair comparison, we followed these principles:
- We compiled a list of all open-source PRs, 17 to be precise and reviewed each of them with both Panto AI and CodeAnt.
- We used OpenAI’s o3-mini API (best for coding) to classify comments, rather than relying on human judgment, as code reviews are inherently subjective and prone to bias.
- We eliminated words or tags like Important, Security, or Critical from bot-generated comments to prevent the LLM from being influenced by predefined labels.
By open-sourcing this benchmark, we at Panto AI aim to provide complete transparency and help developers choose the best AI-powered code review tool for their needs. Let the results speak for themselves.
| pantomaxbot[bot] | codeant-ai[bot] | |
| CRITICAL_BUG | 12 | 9 |
| REFACTORING | 14 | 4 |
| PERFORMANCE_OPTIMIZATION | 5 | 0 |
| VALIDATION | 0 | 1 |
| NITPICK | 3 | 3 |
| FALSE_POSITIVE | 4 | 0 |
| OTHER | 0 | 0 |
| SUM | 38 | 17 |
When we first saw the data from CodeAnt AI, we were genuinely impressed. It showed strong performance on Signal-to-Noise Ratio. It flags issues when they’re critical, but here comes the bias: the bias of what you expect from a code reviewer. CodeAnt performs well in statistical analysis and flags overlooked security nuances. If that’s all you’re expecting from code reviews, CodeAnt works well.
It provides roughly half the number of comments compared to other tools in this space. Most of these resemble what you’d typically see on CI/CD pipelines or in dashboards from SAST tools like SonarQube. As their team rightly mentions, it’s meant to replace SonarQube—but it doesn’t quite do the job of a full-fledged code review.
In the critical category, Panto flagged 30% more comments than CodeAnt. These were some of our favourites.
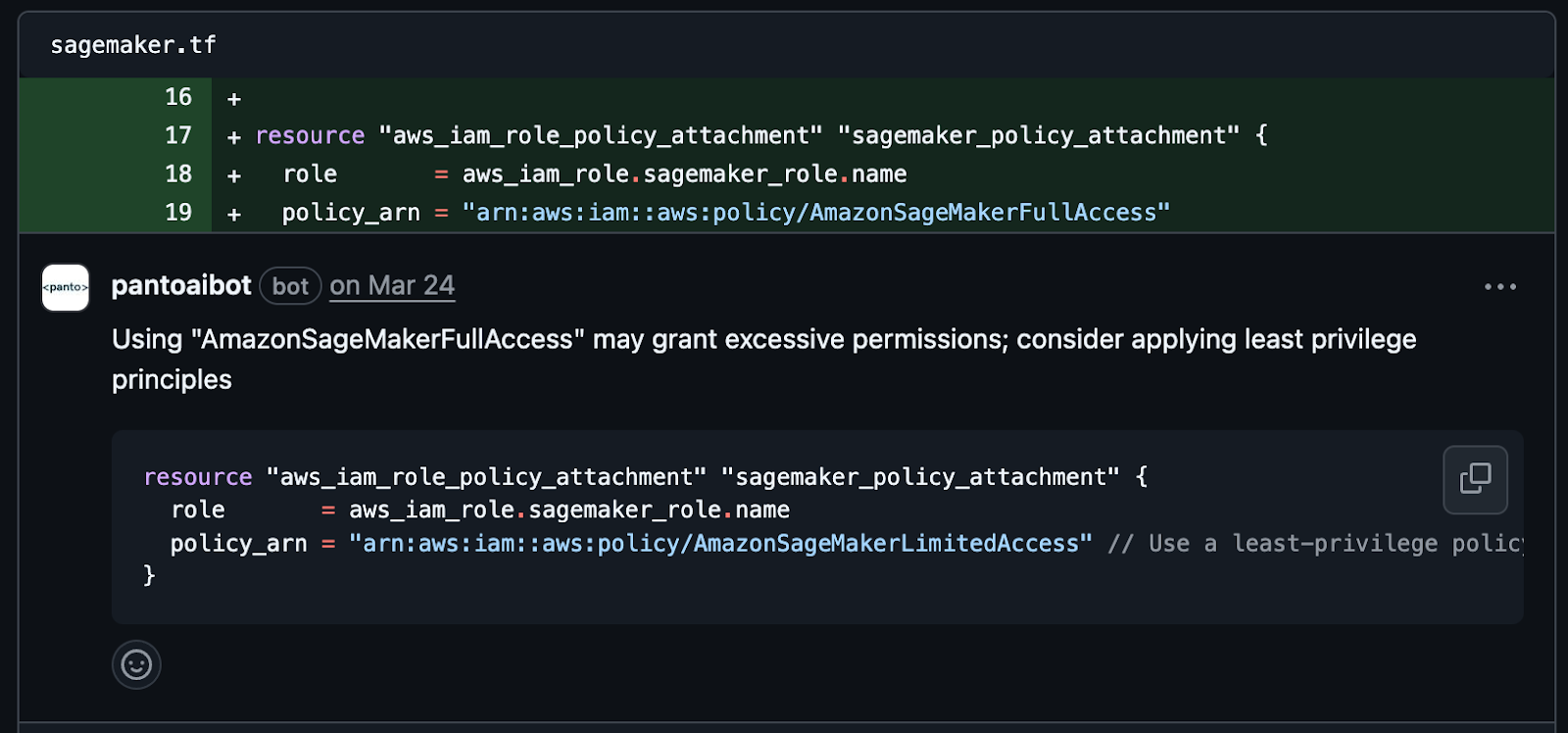
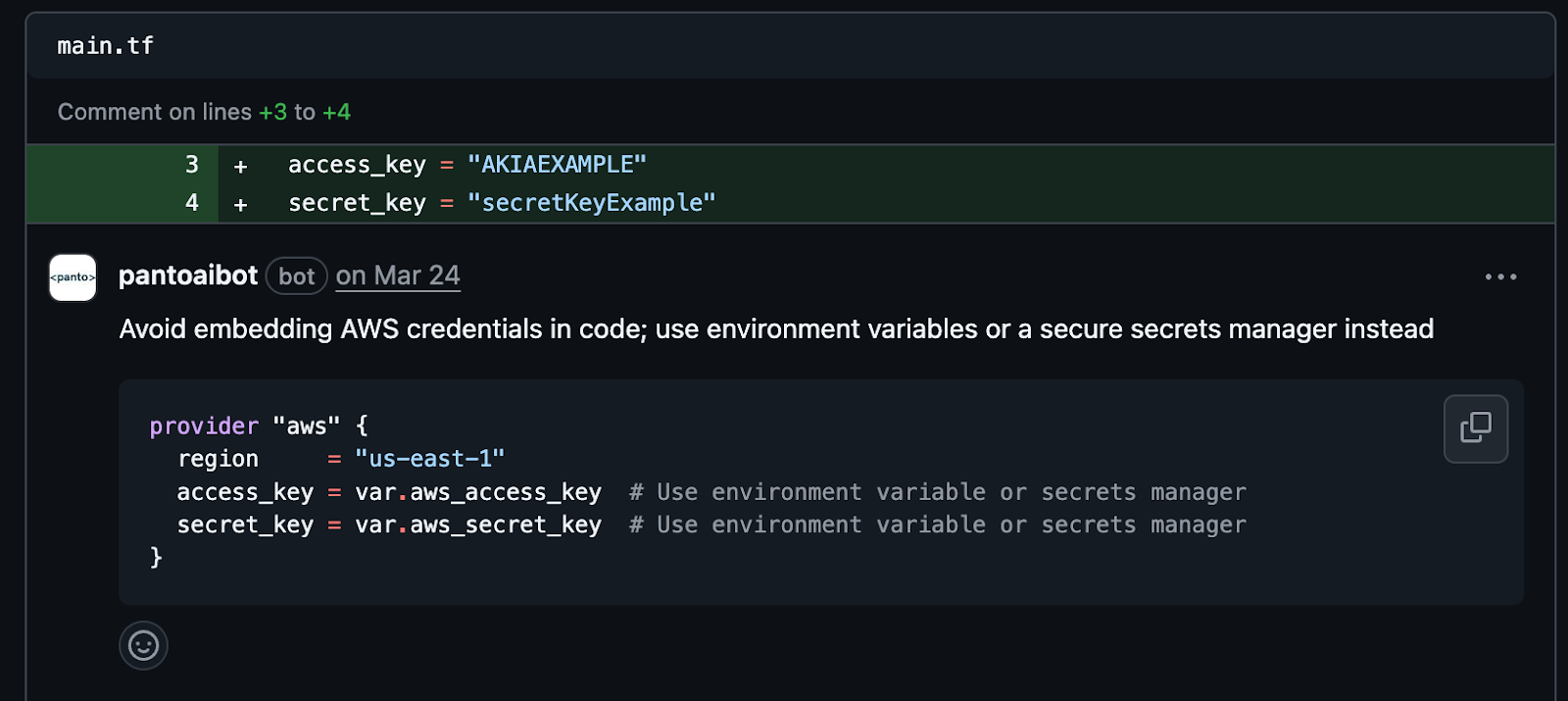
Performance optimization involves improving runtime efficiency without altering functionality. Refactoring is about restructuring code to improve readability and maintainability without changing behavior. Panto’s suggestions were context-aware, minimized churn, and preserved intent far better than CodeAnt AI. Panto identified bottlenecks more accurately and suggested 5x more actionable changes with measurable impact.
These were our favourites:
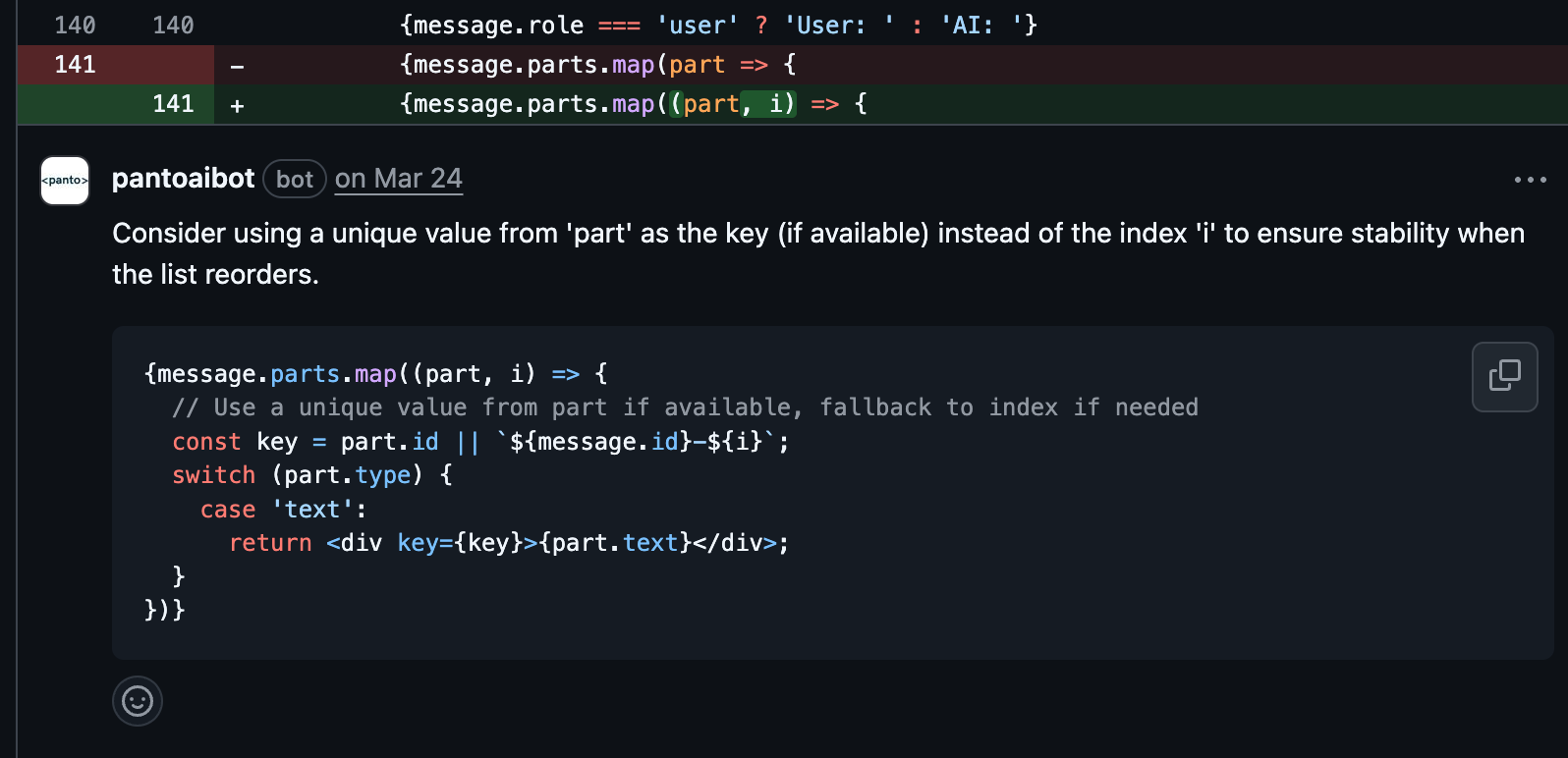
In nitpicking the type of comments, both agents provided the same kind of comments. At Panto, although we provide nitpick comments at the end of PR making it optional devs to glance or ignore where as code ant provides a tag but some time is spent on reading.
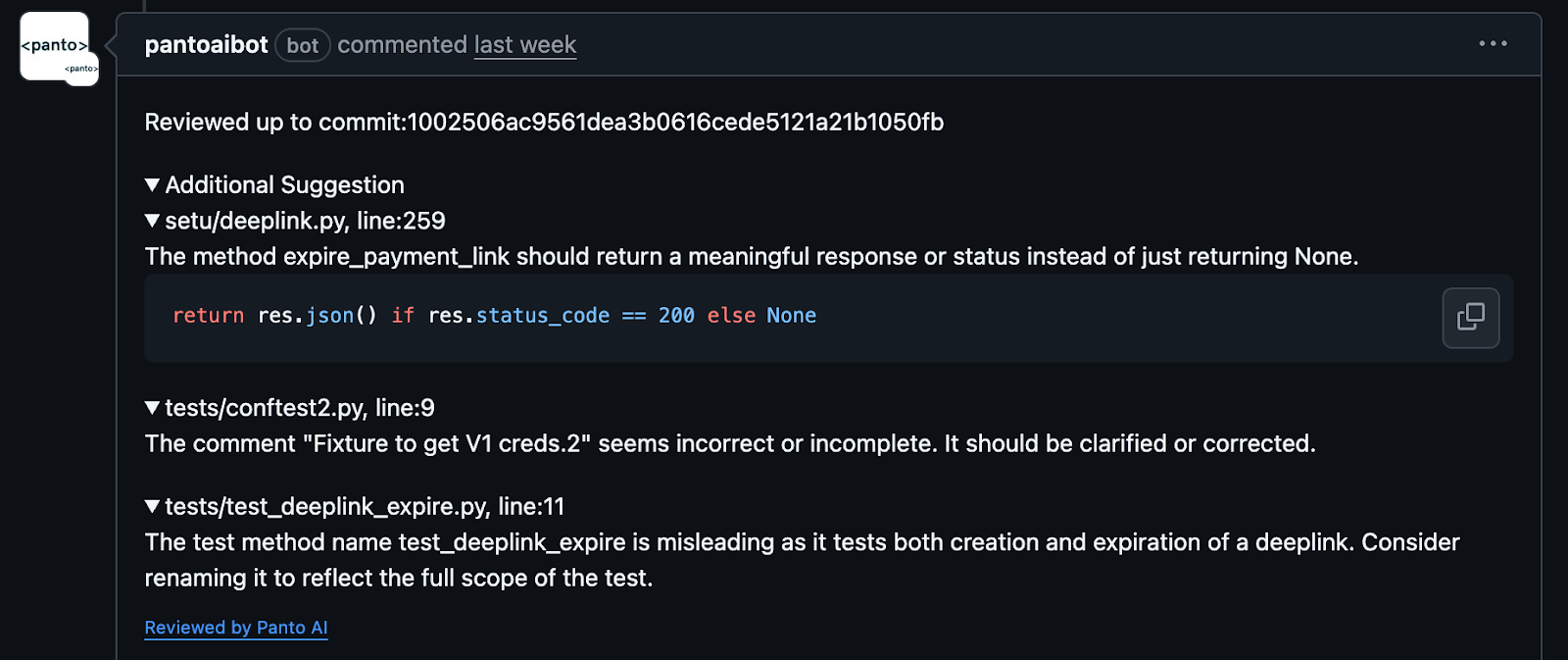
CodeAnt AI scored an absolute home run by having zero false positives, whereas Panto AI had four comments that were false positives. Now comes the subjective part of code review agents—if the priority is overall coverage, we need to provide enough context while seeking comments. This naturally leads to more suggestions, but it’s often better to be warned than to miss something critical.
One size doesn’t fit all, and each of these products suits different kinds of teams. If you’re simply looking to upgrade your statistical analysis tooling, your approach would be different. But if you’re expecting a full-fledged code review experience, you’ll need to consider a few other key metrics.
Here below is the data for you to take a call: